Equilibrio entre precisión y velocidad en sistemas RAG: conocimientos sobre técnicas de recuperación optimizadas

En los últimos tiempos, Generación aumentada de recuperación (RAG) se ha vuelto popular debido a su capacidad para resolver desafíos utilizando modelos de lenguaje grandes, como alucinaciones y datos de entrenamiento obsoletos. Una tubería RAG consta de dos componentes: un perdiguero y un lector. El componente recuperador encuentra información útil en una base de conocimiento externa, que luego se incluye junto con una consulta en un mensaje para el modelo de lector. Este proceso se ha utilizado como una alternativa eficaz a los costosos ajustes, ya que ayuda a reducir los errores cometidos por LLM. Sin embargo, no está claro en qué medida contribuye cada parte de un oleoducto RAG a su desempeño en tareas específicas.
Actualmente, los modelos de recuperación utilizan Incrustación de vectores densos modelos debido a su mejor rendimiento que los métodos más antiguos, ya que se basan en frecuencias de palabras. Estos modelos utilizan algoritmos de búsqueda del vecino más cercano para encontrar documentos que coincidan con una consulta, y los recuperadores más densos codifican cada documento como un único vector. Modelos multivectoriales avanzados como COLBERT permitir mejores interacciones entre el documento y los términos de consulta, lo que podría generalizarse mejor a nuevos conjuntos de datos. Sin embargo, las incrustaciones de vectores densas son ineficientes, especialmente con datos de alta dimensión, lo que ralentiza las búsquedas en bases de datos grandes. Los oleoductos RAG utilizan un vecino más cercano aproximado (ANN) Busque mejorar esto sacrificando algo de precisión para obtener resultados más rápidos. Sin embargo, no existe una guía clara sobre la configuración ANA Busca equilibrar velocidad y precisión.
Un grupo de investigadores del Universidad de Colorado Boulder y laboratorios Intel Realizó una investigación detallada sobre la optimización de las tuberías RAG para tareas comunes como Respuesta a preguntas (QA). Centrándose en comprender el impacto de la recuperación en el rendimiento aguas abajo en los ductos RAG, se evaluaron ductos en los que los componentes del recuperador y LLM fueron capacitados por separado. Se descubrió que el enfoque evita los altos costos de recursos de la capacitación de principio a fin y aclara la contribución del perro perdiguero.
Se realizaron experimentos para evaluar el desempeño de dos programas sintonizados con instrucciones. LLM, Llama y Mistralen tuberías de recuperación-generación aumentada (RAG) sin ajustes ni capacitación adicional. La evaluación se centró principalmente en tareas de control de calidad estándar y de control de calidad atribuido, donde los modelos generaron respuestas utilizando documentos recuperados, e incluyó citas de documentos específicos en el caso de control de calidad atribuido. Modelos de recuperación densos como base BGE y ColBERTv2 se utilizaron para aprovechar la búsqueda eficiente de ANN para incrustaciones densas. Los conjuntos de datos probados incluyeron ASQA, QAMPARIy Preguntas naturales (NQ), diseñado para evaluar las capacidades de recuperación y generación. Las métricas de recuperación se basaron en el recuerdo (recuperador y recuerdo de búsqueda), mientras que la precisión del control de calidad se midió mediante el recuerdo de coincidencia exacta, y los marcos establecidos evaluaron la calidad de las citas a través del recuerdo y la precisión de las citas. Los intervalos de confianza se calcularon mediante bootstrapping para determinar la significación estadística en varias consultas.
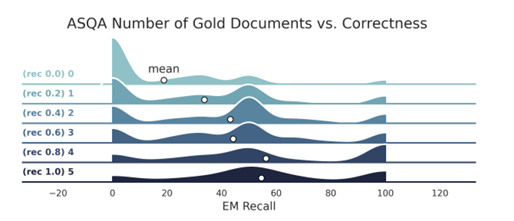
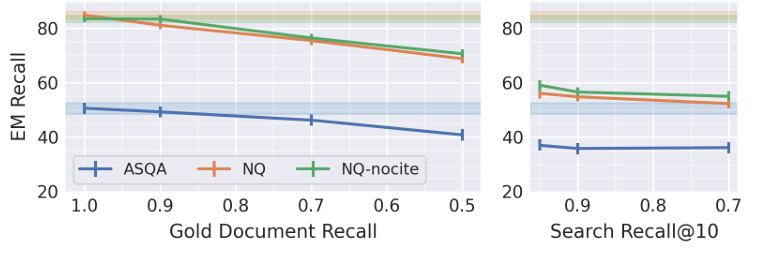
Después de evaluar el desempeño, los investigadores encontraron que la recuperación generalmente mejora el desempeño, con COLBERT ligeramente superior BGE por un pequeño margen. El análisis mostró una corrección óptima con 5-10 documentos recuperados para Mistral, y 4-10 para Llama se logró dependiendo del conjunto de datos. En particular, agregar un mensaje de cita solo afectó significativamente los resultados cuando el número de documentos recuperados (k) superó 10. Para algunos documentos, la precisión de las citas fue más alta y agregar más generó demasiadas citas. La inclusión de documentos dorados mejoró enormemente el rendimiento del control de calidad y redujo el recuerdo de búsqueda de 1.0 a 0,7 tuvo sólo un pequeño impacto. Por lo tanto, los investigadores descubrieron que reducir la precisión de la búsqueda aproximada del vecino más cercano (ANN) en el recuperador tiene efectos mínimos en el desempeño de la tarea. Agregar ruido a los resultados de recuperación también conduce a una disminución del rendimiento. Y no se encontró que la configuración superara el estándar de oro.
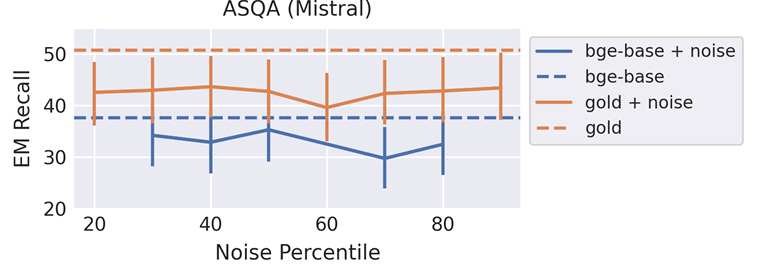
En conclusión, esta investigación proporcionó información útil sobre cómo mejorar las estrategias de recuperación para las canalizaciones RAG y destacó la importancia de los recuperadores para aumentar el rendimiento y la eficiencia, especialmente para las tareas de control de calidad. También demostró que inyectar documentos ruidosos junto con oro o documentos recuperados degrada la corrección en comparación con el techo de oro. En el futuro, la generalidad de los hallazgos de esta investigación se podrá probar en otros entornos y puede servir como base para futuras investigaciones en el campo de las tuberías RAG.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(SEMINARIO WEB GRATUITO sobre IA) Implementación del procesamiento inteligente de documentos con GenAI en servicios financieros y transacciones inmobiliarias– Del marco a la producción
Divyesh es pasante de consultoría en Marktechpost. Está cursando un BTech en Ingeniería Agrícola y Alimentaria en el Instituto Indio de Tecnología de Kharagpur. Es un entusiasta de la ciencia de datos y el aprendizaje automático que quiere integrar estas tecnologías líderes en el ámbito agrícola y resolver desafíos.
🐝🐝 Evento de LinkedIn, ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.