Este artículo de IA de UC Berkeley presenta Pie: un marco de aprendizaje automático para el intercambio transparente de rendimiento y la expansión adaptativa en inferencia LLM

El uso de grandes modelos de lenguaje (LLM) ha revolucionado las aplicaciones de inteligencia artificial, permitiendo avances en tareas de procesamiento del lenguaje natural como la IA conversacional, la generación de contenido y la finalización automatizada de código. A menudo, con miles de millones de parámetros, estos modelos dependen de enormes recursos de memoria para almacenar estados de cálculo intermedios y grandes cachés de valores-clave durante la inferencia. La intensidad computacional y el tamaño creciente de estos modelos exigen soluciones innovadoras para administrar la memoria sin sacrificar el rendimiento.
Un desafío crítico con los LLM es la capacidad de memoria limitada de las GPU. Cuando la memoria de la GPU se vuelve insuficiente para almacenar los datos necesarios, los sistemas descargan partes de la carga de trabajo a la memoria de la CPU, un proceso conocido como intercambio. Si bien esto amplía la capacidad de la memoria, introduce retrasos debido a la transferencia de datos entre CPU y GPU, lo que afecta significativamente el rendimiento y la latencia de la inferencia LLM. La compensación entre aumentar la capacidad de memoria y mantener la eficiencia informática sigue siendo un cuello de botella clave para avanzar en la implementación de LLM a escala.
Las soluciones actuales como vLLM y FlexGen intentan abordar este problema mediante varias técnicas de intercambio. vLLM emplea una estructura de memoria paginada para administrar la caché de valores-clave, lo que mejora hasta cierto punto la eficiencia de la memoria. FlexGen, por otro lado, utiliza perfiles fuera de línea para optimizar la asignación de memoria entre GPU, CPU y recursos de disco. Sin embargo, estos enfoques a menudo necesitan una latencia más predecible, cálculos retrasados y una incapacidad para adaptarse dinámicamente a los cambios en la carga de trabajo, lo que deja espacio para una mayor innovación en la gestión de la memoria.
Investigadores de UC Berkeley presentaron Pie, un novedoso marco de inferencia diseñado para superar los desafíos de las limitaciones de memoria en los LLM. Pie emplea dos técnicas principales: intercambio transparente de rendimiento y expansión adaptativa. Aprovechando patrones predecibles de acceso a la memoria y funciones avanzadas de hardware como el NVLink de gran ancho de banda del Superchip Grace Hopper NVIDIA GH200, Pie extiende dinámicamente la capacidad de la memoria sin agregar retrasos computacionales. Este enfoque innovador permite que el sistema enmascare las latencias de transferencia de datos ejecutándolas simultáneamente con los cálculos de la GPU, lo que garantiza un rendimiento óptimo.
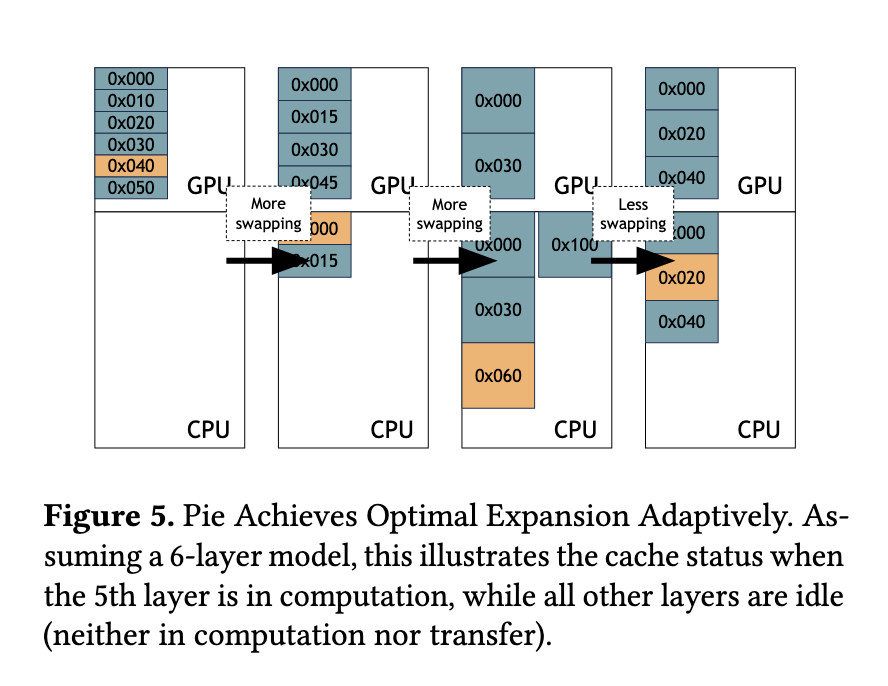
La metodología de Pie gira en torno a dos componentes fundamentales. El intercambio transparente en el rendimiento garantiza que las transferencias de memoria no retrasen los cálculos de la GPU. Esto se logra precargando datos en la memoria de la GPU antes de su uso, utilizando el gran ancho de banda de las GPU y CPU modernas. Mientras tanto, la expansión adaptativa ajusta la cantidad de memoria de la CPU utilizada para el intercambio en función de las condiciones del sistema en tiempo real. Al asignar memoria dinámicamente según sea necesario, Pie evita la subutilización o el intercambio excesivo que podría degradar el rendimiento. Este diseño permite a Pie integrar perfectamente la memoria de CPU y GPU, tratando eficazmente los recursos combinados como un único grupo de memoria ampliado para la inferencia LLM.
Las evaluaciones experimentales de Pie demostraron mejoras notables en las métricas de desempeño. En comparación con vLLM, Pie logró un rendimiento hasta 1,9 veces mayor y una latencia 2 veces menor en varios puntos de referencia. Además, Pie redujo el uso de la memoria de la GPU en 1,67 veces manteniendo un rendimiento comparable. Frente a FlexGen, Pie mostró una ventaja aún mayor, logrando un rendimiento hasta 9,4 veces mayor y una latencia significativamente reducida, particularmente en escenarios que involucran indicaciones más grandes y cargas de trabajo de inferencia más complejas. Los experimentos utilizaron modelos de última generación, incluidos OPT-13B y OPT-30B, y se ejecutaron en instancias NVIDIA Grace Hopper con hasta 96 GB de memoria HBM3. El sistema manejó de manera eficiente cargas de trabajo del mundo real a partir de conjuntos de datos como ShareGPT y Alpaca, lo que demuestra su viabilidad práctica.
La capacidad de Pie para adaptarse dinámicamente a diferentes cargas de trabajo y entornos de sistemas lo distingue de los métodos existentes. El mecanismo de expansión adaptativa identifica rápidamente la configuración óptima de asignación de memoria durante el tiempo de ejecución, lo que garantiza una latencia mínima y un rendimiento máximo. Incluso en condiciones de memoria limitada, el intercambio transparente de rendimiento de Pie permite la utilización eficiente de los recursos, evitando cuellos de botella y manteniendo una alta capacidad de respuesta del sistema. Esta adaptabilidad fue particularmente evidente durante escenarios de alta carga, donde Pie escaló de manera efectiva para satisfacer la demanda sin comprometer el rendimiento.

Pie representa un avance significativo en la infraestructura de IA al abordar el desafío de larga data de las limitaciones de memoria en la inferencia LLM. Su capacidad para ampliar sin problemas la memoria de la GPU con una latencia mínima allana el camino para implementar modelos de lenguaje más grandes y complejos en el hardware existente. Esta innovación mejora la escalabilidad de las aplicaciones LLM y reduce las barreras de costos asociadas con la actualización del hardware para satisfacer las demandas de las cargas de trabajo modernas de IA. A medida que los LLM crezcan en escala y aplicación, marcos como Pie permitirán un uso eficiente y generalizado.
Consulte el documento. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
Por qué los modelos de lenguaje de IA siguen siendo vulnerables: información clave del informe de Kili Technology sobre las vulnerabilidades de los modelos de lenguaje grandes (Lea el informe técnico completo aquí)
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.
🐝🐝 Evento de LinkedIn, ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.