Conozca FluidML: un marco genérico de optimización y gestión de memoria en tiempo de ejecución para una inferencia de aprendizaje automático más rápida e inteligente

La implementación de modelos de aprendizaje automático en dispositivos perimetrales plantea desafíos importantes debido a los recursos computacionales limitados. Cuando el tamaño y la complejidad de los modelos aumentan, incluso lograr una inferencia eficiente se vuelve un desafío. Aplicaciones como vehículos autónomos, gafas AR y robots humanoides requieren operaciones de baja latencia y memoria eficiente. En tales aplicaciones, los enfoques actuales no logran manejar ni siquiera la sobrecarga computacional y de memoria provocada por arquitecturas intrincadas como transformadores o modelos básicos, lo que hace que la inferencia en tiempo real y con conocimiento de los recursos sea una necesidad crítica.
Para superar estos desafíos, los investigadores han desarrollado métodos como la poda, la cuantificación y la destilación de conocimientos para reducir el tamaño del modelo y técnicas a nivel de sistema como la fusión de operadores y el plegado constante. Aunque son efectivos en escenarios específicos, estos enfoques a menudo se centran en optimizaciones únicas, ignorando la posibilidad de optimizar conjuntamente todos los gráficos computacionales. Las técnicas tradicionales de gestión de memoria en marcos estándar respetan poco las conexiones y configuraciones de las redes neuronales contemporáneas, lo que lleva a un rendimiento mucho menor que el óptimo en aplicaciones a gran escala.
FluidML es un marco innovador para la optimización de la inferencia que transforma de manera integral los planos de ejecución de modelos. Se centra en la integración de operadores de gráficos junto con la optimización de los diseños de memoria en gráficos computacionales, utiliza programación dinámica para una programación eficiente en tiempo de ejecución y medios de acceso avanzado a la memoria, como la reordenación de bucles para tareas computacionalmente exigentes, como la multiplicación de matrices. FluidML proporciona compatibilidad multiplataforma de un extremo a otro mediante el uso de una interfaz basada en ONNX y una compilación basada en LLVM para admitir muchos operadores e inferir bien para la mayoría de las aplicaciones.
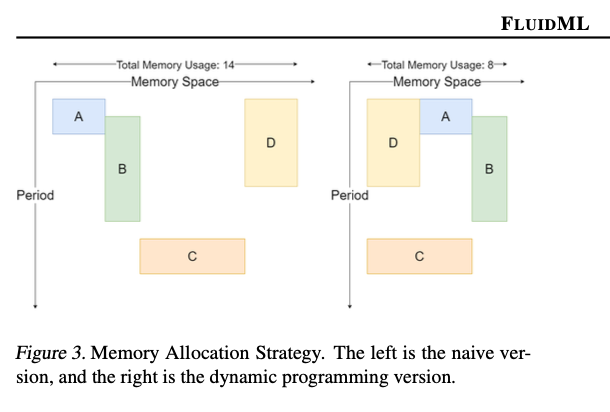
FluidML utiliza técnicas avanzadas para mejorar la ejecución de inferencias. Identifica las secuencias computacionales más largas en un gráfico y las segmenta en subgrafos para una optimización recursiva mediante programación dinámica. Se programan diseños de memoria eficientes para las secuencias de ejecución y los conflictos se resuelven mediante mecanismos de votación basados en dependencias. FluidML se basa en MLIR y LLVM IR, lo que permite una inclusión perfecta en los flujos de trabajo existentes para minimizar los gastos generales y maximizar el rendimiento. Esto mejorará el uso de la caché y el tiempo para completar operaciones que consumen mucha memoria, como la multiplicación de matrices y la convolución.
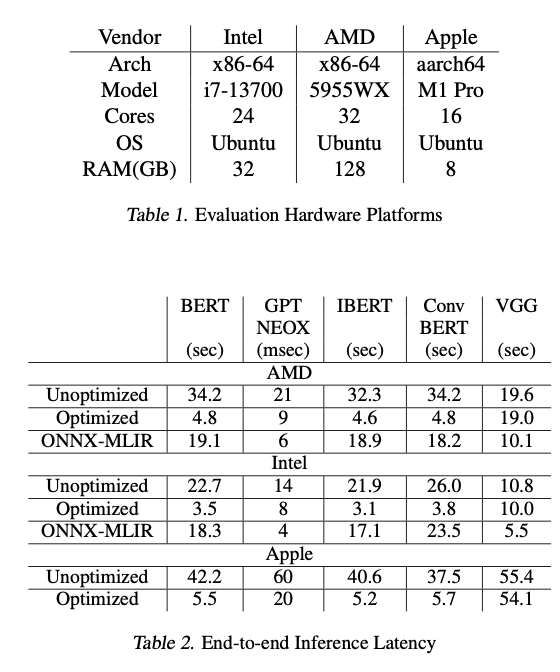
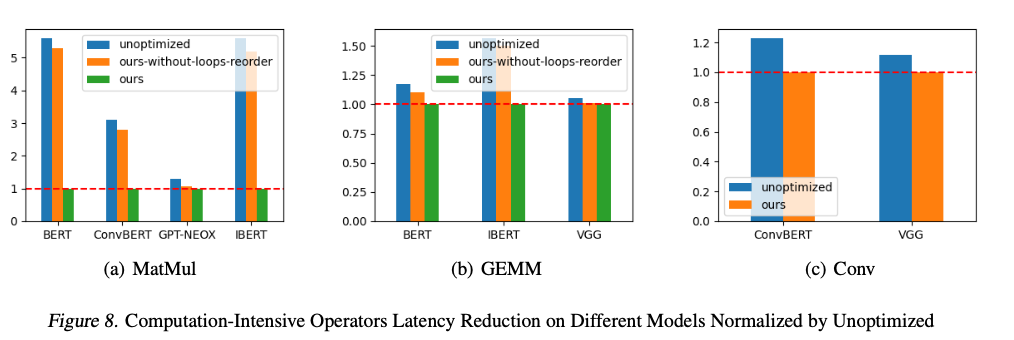
FluidML proporcionó importantes mejoras de rendimiento, logrando una reducción de hasta un 25,38 % en la latencia de inferencia y una reducción de hasta un 41,47 % en el uso máximo de memoria en múltiples plataformas de hardware. Estas mejoras fueron consistentes en todos los modelos, desde modelos de lenguaje basados en transformadores como BERT y GPT-NEOX hasta modelos de visión como VGG. A través de una estrategia de diseño de memoria optimizada y la ejecución optimizada de operaciones computacionalmente costosas, FluidML estableció superioridad en comparación con ONNX-MLIR y Apache TVM de última generación, lo que lo convierte en una solución sólida y eficiente para entornos con recursos limitados.
En conclusión, FluidML proporciona contexto para la optimización revolucionaria del tiempo de ejecución de inferencia y el uso de la memoria en entornos informáticos de vanguardia. El diseño holístico integra en una sola pieza coherente la optimización del diseño de la memoria, la segmentación de gráficos y técnicas superiores de programación, algunas de las cuales llenan un vacío dejado por las soluciones actuales. Las enormes ganancias en latencia y eficiencia de la memoria ayudan en la implementación en tiempo real de modelos complejos de aprendizaje automático, incluso en casos de uso con recursos muy limitados.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(CONFERENCIA VIRTUAL DE IA GRATUITA) SmallCon: Conferencia virtual gratuita sobre GenAI con Meta, Mistral, Salesforce, Harvey AI y más. Únase a nosotros el 11 de diciembre en este evento virtual gratuito para aprender lo que se necesita para construir a lo grande con modelos pequeños de pioneros de la IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face y más.
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el aprendizaje automático, y aporta una sólida formación académica y experiencia práctica en la resolución de desafíos interdisciplinarios de la vida real.
🐝🐝 Evento de LinkedIn, ‘Una plataforma, posibilidades multimodales’, donde el director ejecutivo de Encord, Eric Landau, y el director de ingeniería de productos, Justin Sharps, hablarán sobre cómo están reinventando el proceso de desarrollo de datos para ayudar a los equipos a construir rápidamente modelos de IA multimodales innovadores.