Se lanzó Jina-Embeddings-v3: un modelo de incrustación de texto multilingüe y multitarea diseñado para una variedad de aplicaciones de PNL

Los modelos de incrustación de texto se han vuelto fundamentales en el procesamiento del lenguaje natural (PLN). Estos modelos convierten el texto en vectores de alta dimensión que capturan relaciones semánticas, lo que permite tareas como la recuperación de documentos, la clasificación, la agrupación y más. Las incrustaciones son especialmente críticas en sistemas avanzados como los modelos de recuperación-generación aumentada (RAG), donde las incrustaciones respaldan la recuperación de documentos relevantes. Con la creciente necesidad de modelos que puedan manejar múltiples idiomas y secuencias de texto largas, los modelos basados en transformadores han revolucionado la forma en que se generan las incrustaciones. Sin embargo, si bien estos modelos tienen capacidades avanzadas, enfrentan limitaciones en aplicaciones del mundo real, particularmente en el manejo de datos multilingües extensos y documentos de contexto largo.
Los modelos de incrustación de texto se han enfrentado a varios desafíos en los últimos años. Si bien se anuncian como de uso general, un problema clave es que muchos modelos a menudo requieren un ajuste específico para funcionar bien en diversas tareas. Estos modelos con frecuencia tienen dificultades para equilibrar el rendimiento en diferentes idiomas y manejar secuencias de texto largas. En aplicaciones multilingües, los modelos de incrustación deben lidiar con la complejidad de las relaciones de codificación en diferentes idiomas, cada uno con estructuras lingüísticas únicas. La dificultad aumenta con las tareas que requieren el procesamiento de secuencias de texto extensas, que a menudo exceden la capacidad de la mayoría de los modelos actuales. Además, la implementación de estos modelos a gran escala, a menudo con miles de millones de parámetros, presenta importantes desafíos de escalabilidad y costo computacional, especialmente cuando las mejoras marginales no justifican el consumo de recursos.
Los intentos anteriores de resolver estos desafíos se han basado en gran medida en modelos de lenguaje grandes (LLM), que pueden superar los 7 mil millones de parámetros. Estos modelos han demostrado su capacidad para gestionar diversas tareas en diferentes idiomas, desde la clasificación de texto hasta la recuperación de documentos. Sin embargo, a pesar de su gran tamaño de parámetros, las mejoras de rendimiento son mínimas en comparación con los modelos que solo incluyen codificadores, como XLM-RoBERTa y mBERT. La complejidad de estos modelos también los hace poco prácticos para muchas aplicaciones del mundo real en las que los recursos son limitados. Los esfuerzos para hacer que las incrustaciones sean más eficientes han incluido innovaciones como el ajuste de instrucciones y los métodos de codificación posicional, como las incrustaciones de posición rotatoria (RoPE), que ayudan a los modelos a procesar secuencias de texto más largas. Sin embargo, incluso con estos avances, los modelos a menudo no logran satisfacer las demandas de las tareas de recuperación multilingües del mundo real con la eficiencia deseada.
Los investigadores de Jina AI GmbH han presentado un nuevo modelo, Jina-incrustaciones-v3diseñado específicamente para abordar las ineficiencias de los modelos de incrustación anteriores. Este modelo, que incluye 570 millones de parámetros, ofrece un rendimiento optimizado en múltiples tareas y, al mismo tiempo, admite documentos de contexto más extenso de hasta 8192 tokens. El modelo incorpora una innovación clave: adaptadores de adaptación de bajo rango (LoRA) específicos de la tarea. Estos adaptadores permiten que el modelo genere de manera eficiente incrustaciones de alta calidad para varias tareas, incluida la recuperación de documentos de consulta, la clasificación, la agrupación y la coincidencia de texto. La capacidad de Jina-embeddings-v3 de proporcionar optimizaciones específicas para estas tareas garantiza un manejo más efectivo de datos multilingües, documentos extensos y escenarios de recuperación complejos, equilibrando el rendimiento y la escalabilidad.
La arquitectura del modelo Jina-embeddings-v3 se basa en el ampliamente reconocido modelo XLM-RoBERTa, pero con varias mejoras críticas. Utiliza FlashAttention 2 para mejorar la eficiencia computacional e integra incrustaciones posicionales RoPE para manejar tareas de contexto largo de hasta 8192 tokens. Una de las características más innovadoras del modelo es el aprendizaje de representación Matryoshka, que permite a los usuarios truncar incrustaciones sin comprometer el rendimiento. Este método proporciona flexibilidad para elegir diferentes tamaños de incrustación, como reducir una incrustación de 1024 dimensiones a solo 16 o 32 dimensiones, optimizando el equilibrio entre la eficiencia del espacio y el rendimiento de la tarea. Con la adición de adaptadores LoRA específicos de la tarea, que representan menos del 3% de los parámetros totales, el modelo puede adaptarse dinámicamente a diferentes tareas, como la clasificación y la recuperación. Al congelar los pesos del modelo original, los investigadores han asegurado que el entrenamiento de estos adaptadores siga siendo altamente eficiente, utilizando solo una fracción de la memoria requerida por los modelos tradicionales. Esta eficiencia lo hace práctico para su implementación en entornos del mundo real.
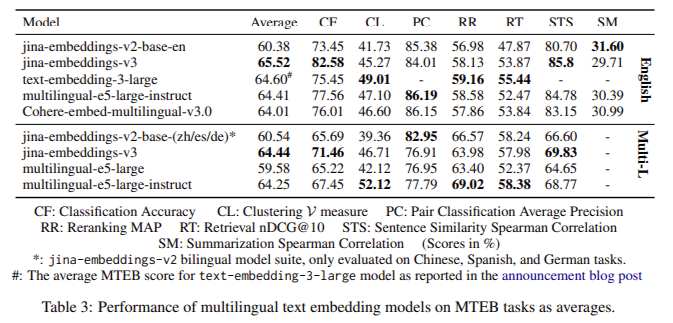
El modelo Jina-embeddings-v3 ha mostrado mejoras notables en el rendimiento en varias pruebas comparativas. El modelo superó a competidores como los modelos propietarios de OpenAI y las incrustaciones multilingües de Cohere en evaluaciones multilingües, particularmente en tareas en inglés. El modelo jina-embeddings-v3 demostró resultados superiores en precisión de clasificación (82,58 %) y similitud de oraciones (85,8 %) en el benchmark MTEB, superando a modelos mucho más grandes como e5-mistral-7b-instruct, que tiene más de 7 mil millones de parámetros pero solo muestra una mejora marginal del 1 % en ciertas tareas. Jina-embeddings-v3 logró excelentes resultados en tareas multilingües, superando a multilingual-e5-large-instruct en todas las tareas a pesar de su tamaño significativamente más pequeño. Su capacidad para funcionar bien en tareas de recuperación de contextos largos y multilingües al tiempo que requiere menos recursos computacionales lo hace altamente eficiente y rentable, especialmente para aplicaciones informáticas rápidas y de borde.

En conclusión, Jina-embeddings-v3 ofrece una solución escalable y eficiente a los desafíos de larga data que enfrentan los modelos de incrustación de texto en tareas multilingües y de contexto largo. La integración de adaptadores LoRA, aprendizaje de representación Matryoshka y otras técnicas avanzadas garantiza que el modelo pueda manejar varias funciones sin la carga computacional excesiva que se observa en modelos con miles de millones de parámetros. Los investigadores han creado un modelo práctico y de alto rendimiento que supera a muchos modelos más grandes y establece un nuevo estándar para la eficiencia de incrustación. La introducción de estas innovaciones proporciona un camino claro hacia adelante para futuros avances en la recuperación multilingüe y de texto largo, lo que convierte a jina-embeddings-v3 en una herramienta valiosa en NLP.
Echa un vistazo a la Papel y Tarjeta modelo en HFTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)