Este artículo de inteligencia artificial de NVIDIA presenta NVLM 1.0: una familia de modelos de lenguaje multimodales de gran tamaño con capacidades mejoradas de procesamiento de texto e imágenes

Los modelos de lenguaje multimodales de gran tamaño (MLLM, por sus siglas en inglés) se centran en la creación de sistemas de inteligencia artificial (IA) capaces de interpretar datos textuales y visuales sin problemas. Estos modelos tienen como objetivo cerrar la brecha entre la comprensión del lenguaje natural y la comprensión visual, permitiendo que las máquinas procesen de manera cohesiva diversas formas de entrada, desde documentos de texto hasta imágenes. La comprensión y el razonamiento a través de múltiples modalidades se está volviendo crucial, especialmente a medida que la IA avanza hacia aplicaciones más sofisticadas en áreas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la visión artificial. Al mejorar la forma en que la IA integra y procesa diversas fuentes de datos, los MLLM están listos para revolucionar tareas como el subtitulado de imágenes, la comprensión de documentos y los sistemas de IA interactivos.
Un desafío importante en el desarrollo de modelos multimodales de inteligencia artificial es asegurar que funcionen igualmente bien en tareas basadas en texto y en lenguaje visual. A menudo, las mejoras en un área pueden llevar a una disminución en la otra. Por ejemplo, mejorar la comprensión visual de un modelo puede afectar negativamente sus capacidades lingüísticas, lo que es problemático para aplicaciones que requieren ambas, como el reconocimiento óptico de caracteres (OCR) o el razonamiento multimodal complejo. La cuestión clave es equilibrar el procesamiento de datos visuales, como imágenes de alta resolución, y mantener un razonamiento textual sólido. A medida que las aplicaciones de IA se vuelven más avanzadas, esta disyuntiva se convierte en un cuello de botella crítico en el progreso de los modelos de IA multimodales.
Los enfoques existentes para los MLLM, incluidos modelos como GPT-4V e InternVL, han intentado abordar este problema utilizando diversas técnicas de arquitectura. Estos modelos congelan el modelo de lenguaje durante el entrenamiento o emplean mecanismos de atención cruzada para procesar tokens de imagen y texto simultáneamente. Sin embargo, estos métodos no están exentos de fallas. Congelar el modelo de lenguaje durante el entrenamiento multimodal a menudo da como resultado un rendimiento deficiente en tareas de visión-lenguaje. En contraste, los modelos de acceso abierto como LLaVA-OneVision e InternVL han mostrado una marcada degradación en el rendimiento de solo texto después del entrenamiento multimodal. Esto refleja un problema persistente en el campo, donde los avances en una modalidad se producen a expensas de otra.
Los investigadores de NVIDIA han presentado los modelos NVLM 1.0, que representan un avance significativo en el modelado de lenguaje multimodal. La familia NVLM 1.0 consta de tres arquitecturas principales: NVLM-D, NVLM-X y NVLM-H. Cada uno de estos modelos aborda las deficiencias de los enfoques anteriores al integrar capacidades avanzadas de razonamiento multimodal con un procesamiento de texto eficiente. Una característica notable de NVLM 1.0 es la inclusión de datos de ajuste fino supervisado (SFT) de solo texto de alta calidad durante el entrenamiento, lo que permite que estos modelos mantengan e incluso mejoren su rendimiento solo con texto al tiempo que sobresalen en tareas de visión y lenguaje. El equipo de investigación destacó que su enfoque está diseñado para superar los modelos propietarios existentes como GPT-4V y las alternativas de acceso abierto como InternVL.
Los modelos NVLM 1.0 emplean una arquitectura híbrida para equilibrar el procesamiento de texto e imágenes. NVLM-D, el modelo que solo incluye decodificador, maneja ambas modalidades de manera unificada, lo que lo hace particularmente adecuado para tareas de razonamiento multimodal. NVLM-X, por otro lado, está construido utilizando mecanismos de atención cruzada, que mejoran la eficiencia computacional al procesar imágenes de alta resolución. El modelo híbrido, NVLM-H, combina las fortalezas de ambos enfoques, lo que permite una comprensión más detallada de las imágenes al tiempo que conserva la eficiencia necesaria para el razonamiento de texto. Estos modelos incorporan mosaicos dinámicos para fotos de alta resolución, lo que mejora significativamente el rendimiento en tareas relacionadas con OCR sin sacrificar las capacidades de razonamiento. La integración de un sistema de etiquetado de mosaicos 1-D permite un procesamiento preciso de tokens de imagen, lo que aumenta el rendimiento en tareas como la comprensión de documentos y la lectura de texto de escenas.
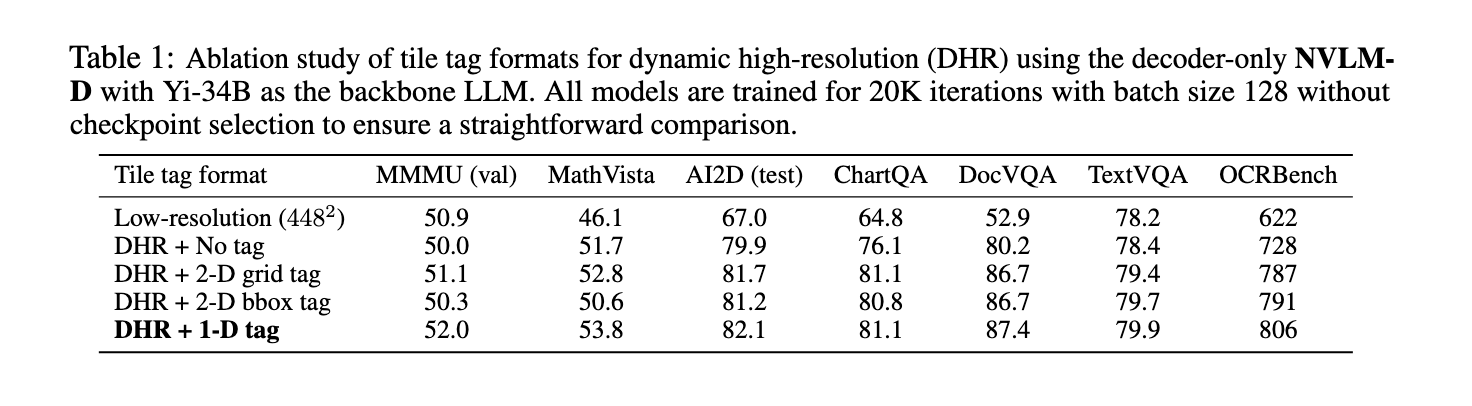
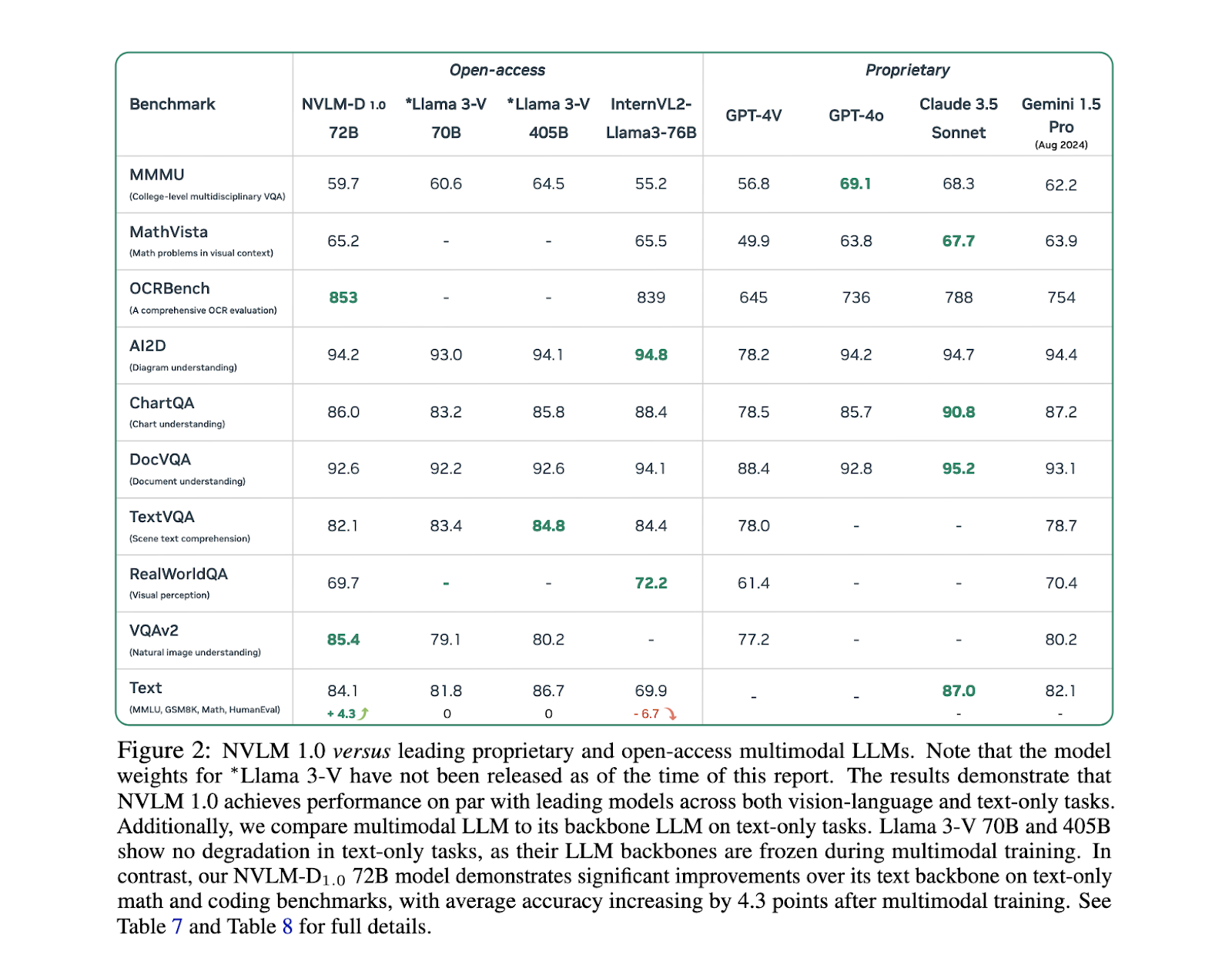
En cuanto al rendimiento, los modelos NVLM 1.0 han logrado resultados impresionantes en múltiples pruebas comparativas. Por ejemplo, en tareas de solo texto como MATH y GSM8K, el modelo NVLM-D1.0 72B experimentó una mejora de 4,3 puntos con respecto a su versión principal de solo texto, gracias a la integración de conjuntos de datos de texto de alta calidad durante el entrenamiento. Los modelos también demostraron un sólido rendimiento en visión y lenguaje, con puntuaciones de precisión del 93,6 % en el conjunto de datos VQAv2 y del 87,4 % en AI2D para tareas de razonamiento y respuesta a preguntas visuales. En tareas relacionadas con OCR, los modelos NVLM superaron significativamente a los sistemas existentes, con una puntuación del 87,4 % en DocVQA y del 81,7 % en ChartQA, lo que destaca su capacidad para manejar información visual compleja. Estos resultados fueron logrados por los modelos NVLM-X y NVLM-H, que demostraron un manejo superior de imágenes de alta resolución y datos multimodales.
Uno de los hallazgos clave de la investigación es que los modelos NVLM no solo sobresalen en tareas de visión-lenguaje, sino que también mantienen o mejoran su desempeño en tareas de solo texto, algo que otros modelos multimodales tienen dificultades para lograr. Por ejemplo, en tareas de razonamiento basadas en texto como MMLU, los modelos NVLM mantuvieron altos niveles de precisión, incluso superando a sus contrapartes de solo texto en algunos casos. Esto es particularmente importante para aplicaciones que requieren una comprensión de texto sólida junto con el procesamiento de datos visuales, como el análisis de documentos y el razonamiento de imagen-texto. El modelo NVLM-H, en particular, logra un equilibrio entre la eficiencia del procesamiento de imágenes y la precisión del razonamiento multimodal, lo que lo convierte en uno de los modelos más prometedores en este campo.
En conclusión, los modelos NVLM 1.0 desarrollados por investigadores de NVIDIA representan un avance significativo en los modelos multimodales de lenguaje de gran tamaño. Al integrar conjuntos de datos de texto de alta calidad en el entrenamiento multimodal y emplear diseños arquitectónicos innovadores como mosaicos dinámicos y etiquetado de mosaicos para imágenes de alta resolución, estos modelos abordan el desafío crítico de equilibrar el procesamiento de texto e imágenes sin sacrificar el rendimiento. La familia de modelos NVLM no solo supera a los principales sistemas propietarios en tareas de visión y lenguaje, sino que también mantiene capacidades superiores de razonamiento solo de texto, lo que marca una nueva frontera en el desarrollo de sistemas de IA multimodales.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Nikhil es consultor en prácticas en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA y el aprendizaje automático que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de los materiales, está explorando nuevos avances y creando oportunidades para contribuir.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)