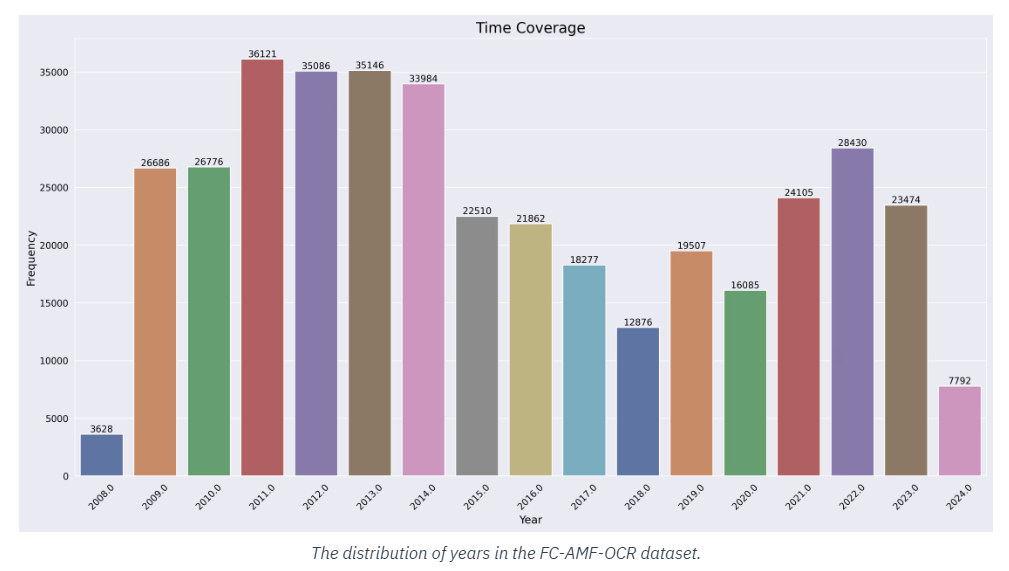
LightOn lanza el conjunto de datos FC-AMF-OCR: un conjunto de datos de 9,3 millones de imágenes de documentos financieros con anotaciones OCR completas

La liberación de la Conjunto de datos FC-AMF-OCR El lanzamiento de LightOn marca un hito importante en el reconocimiento óptico de caracteres (OCR) y el aprendizaje automático. Este conjunto de datos es un logro técnico y una piedra angular para futuras investigaciones en inteligencia artificial (IA) y visión artificial. La introducción de un conjunto de datos de este tipo abre nuevas posibilidades para investigadores y desarrolladores, permitiéndoles mejorar los modelos de OCR, que son esenciales para convertir imágenes de texto en formatos de texto legibles por máquina.
Antecedentes del conjunto de datos LightOn y FC-AMF-OCR
LightOn, una empresa reconocida por sus contribuciones pioneras a la inteligencia artificial y el aprendizaje automático, ha superado continuamente los límites de la tecnología. El conjunto de datos FC-AMF-OCR es uno de sus últimos proyectos, diseñado para facilitar tareas de OCR más precisas y eficientes. Es bien sabido que la tecnología OCR tiene una amplia gama de aplicaciones, desde la digitalización de libros impresos hasta el reconocimiento de texto en tiempo real en dispositivos cotidianos. A pesar de los numerosos avances, el OCR sigue siendo un desafío, en particular en el manejo de fuentes complejas, imágenes con ruido e idiomas diversos.
El conjunto de datos FC-AMF-OCR tiene como objetivo superar estas deficiencias al proporcionar un conjunto amplio y diverso de datos de entrenamiento. Estos datos ayudan a los modelos de IA a aprender y adaptarse a diversos desafíos asociados con el reconocimiento de texto. Al incluir una amplia variedad de fuentes, texturas y condiciones de imagen, LightOn garantiza que el conjunto de datos sea lo suficientemente completo como para abordar muchas de las limitaciones actuales de la tecnología OCR.
Importancia del conjunto de datos
El lanzamiento del conjunto de datos FC-AMF-OCR es especialmente importante debido a su enfoque en las metafuentes AMF o amorfas. Estas metafuentes se caracterizan por sus formas abstractas y fluidas, que pueden plantear desafíos importantes para los modelos de OCR tradicionales. Al incorporar estas fuentes únicas al conjunto de datos, LightOn fomenta el desarrollo de modelos de IA que puedan manejar incluso las tareas de reconocimiento de texto más difíciles.
La tecnología OCR desempeña un papel importante en varios sectores. Por ejemplo, el OCR digitaliza y organiza grandes cantidades de documentos impresos en las industrias jurídica y médica. En la industria editorial, permite la conversión de libros físicos a formatos digitales, lo que hace que la literatura sea más accesible para un público global. La precisión de la tecnología OCR puede afectar directamente a la productividad y la accesibilidad en estos campos. El conjunto de datos FC-AMF-OCR permite a los desarrolladores crear modelos OCR más robustos y versátiles, lo que podría mejorar significativamente estos sectores.
Características técnicas del conjunto de datos
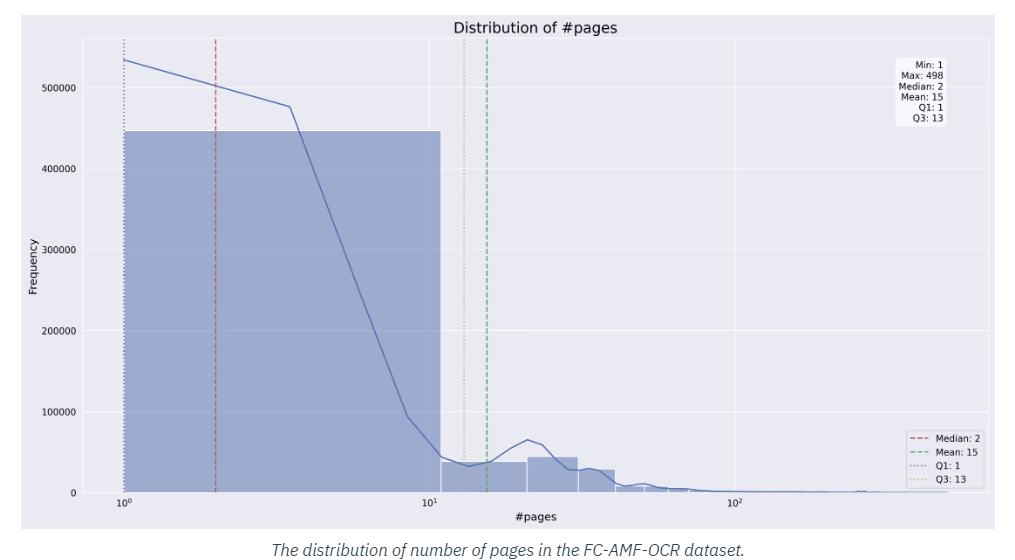
Los aspectos técnicos del conjunto de datos FC-AMF-OCR demuestran su versatilidad y utilidad para los investigadores. El conjunto de datos incluye miles de imágenes, cada una de ellas con diversas formas, que van desde texto digital limpio y nítido hasta fuentes manuscritas y artísticas más complejas. LightOn ha diseñado el conjunto de datos para que se adapte a una amplia gama de casos de uso, incluido el reconocimiento de texto en entornos ruidosos, imágenes distorsionadas y documentos con varios idiomas.
Uno de los componentes más importantes del conjunto de datos es la inclusión de metafuentes amorfas (AMF), que proporcionan un alto grado de variabilidad en los estilos de texto. Estas fuentes no se encuentran normalmente en los conjuntos de datos convencionales, lo que hace que el conjunto de datos FC-AMF-OCR sea único en su capacidad de entrenar modelos de OCR para reconocer formas de texto menos estructuradas y más fluidas. Esto es particularmente beneficioso para las aplicaciones de IA en las industrias creativas, donde el texto a menudo adquiere una forma más artística o no estándar.
El conjunto de datos está diseñado para ser muy accesible y fácil de integrar en los flujos de trabajo de aprendizaje automático existentes. Los investigadores pueden descargar e implementar el conjunto de datos en sus proyectos con una fricción mínima, lo que les permite centrarse en mejorar sus modelos de OCR. El conjunto de datos es compatible con muchos marcos de aprendizaje automático populares, incluidos TensorFlow y PyTorch.
Aplicaciones potenciales
El lanzamiento del conjunto de datos FC-AMF-OCR tiene el potencial de impactar en varias industrias y aplicaciones. Por ejemplo, el OCR reconoce señales de tránsito y otros indicadores basados en texto en sistemas de conducción autónoma. Al agregar fuentes y condiciones más complejas al conjunto de datos FC-AMF-OCR, los desarrolladores podrían mejorar la precisión del reconocimiento de texto en estos entornos, lo que haría que los vehículos autónomos sean más seguros y confiables. Otra área en la que el conjunto de datos podría impactar significativamente en la accesibilidad del contenido digital es la tecnología OCR. La tecnología OCR hace que los materiales impresos sean accesibles para personas con discapacidades visuales. Al mejorar los modelos OCR con el conjunto de datos FC-AMF-OCR, los desarrolladores pueden crear sistemas de texto a voz más precisos que conviertan el texto impreso en voz audible.
El conjunto de datos también promete mejorar la precisión del reconocimiento de texto en aplicaciones de realidad aumentada (RA). La RA depende en gran medida de la tecnología OCR para superponer información digital sobre objetos del mundo real. Por ejemplo, las aplicaciones de RA a menudo muestran traducciones o contexto adicional para el texto que aparece en el entorno del usuario. La capacidad del conjunto de datos FC-AMF-OCR para manejar varias fuentes y estilos de texto podría mejorar significativamente la precisión y la confiabilidad de estas aplicaciones de RA, lo que generaría una experiencia de usuario más fluida.
Desafíos y oportunidades
Si bien el conjunto de datos FC-AMF-OCR representa un gran avance, también destaca los desafíos actuales en el campo del OCR. Uno de los principales desafíos que enfrentan los investigadores es garantizar que los modelos de OCR puedan generalizarse en una amplia gama de estilos de texto y entornos. Si bien el conjunto de datos FC-AMF-OCR incluye muchas fuentes y condiciones, siempre surgirán nuevos desafíos a medida que evolucionen los estilos y formatos de texto. Los investigadores deben adaptar continuamente sus modelos para manejar estilos de texto nuevos y emergentes de manera eficaz.
Además, la complejidad de las fuentes AMF presenta un desafío en cuanto a los recursos computacionales. El entrenamiento de modelos de IA en un conjunto de datos tan diverso y complejo requiere una gran capacidad de procesamiento y memoria. Sin embargo, este desafío también presenta una oportunidad para los avances en el hardware y la infraestructura de IA. El lanzamiento del conjunto de datos FC-AMF-OCR por parte de LightOn también abre la puerta a la colaboración y la innovación. Al poner el conjunto de datos a disposición de investigadores y desarrolladores de forma gratuita, LightOn alienta a la comunidad de IA en general a contribuir al avance de la tecnología OCR.
Conclusión
El lanzamiento del conjunto de datos FC-AMF-OCR por parte de LightOn es un hito en el desarrollo de la tecnología de OCR e IA. Al proporcionar un conjunto de datos completo y diverso que incluye formatos de texto complejos como las metafuentes amorfas, LightOn permite a los investigadores crear modelos de OCR más precisos y versátiles. Las posibles aplicaciones del conjunto de datos abarcan múltiples industrias, desde vehículos autónomos hasta accesibilidad digital, lo que lo convierte en un recurso valioso para futuras investigaciones de IA.
Echa un vistazo a la Conjunto de datos y detallesTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)