DCMAC: comunicación personalizada en función de la demanda para un aprendizaje de refuerzo multiagente eficiente

El aprendizaje colaborativo por refuerzo de múltiples agentes (MARL, por sus siglas en inglés) ha surgido como un enfoque poderoso en varios dominios, incluidos el control de señales de tráfico, la robótica de enjambre y las redes de sensores. Sin embargo, MARL enfrenta desafíos significativos debido a las interacciones complejas entre agentes, que introducen no estacionariedad en el entorno. Esta no estacionariedad complica el proceso de aprendizaje y dificulta que los agentes se adapten a condiciones cambiantes. Además de eso, a medida que aumenta el número de agentes, la escalabilidad se convierte en un problema crítico, que requiere métodos eficientes para manejar sistemas multiagente a gran escala. Por lo tanto, los investigadores se centran en el desarrollo de técnicas que puedan superar estos desafíos y, al mismo tiempo, permitir una colaboración efectiva entre agentes en entornos dinámicos y complejos.
Los intentos anteriores de superar los desafíos de MARL se han centrado predominantemente en dos categorías principales: métodos basados en políticas y métodos basados en valores. Los enfoques de gradiente de políticas como MADDPG, COMA, MAAC, MAPPO, FACMAC y HAPPO han explorado la optimización de gradientes de políticas de múltiples agentes. Los métodos basados en valores como VDN y QMIX se han concentrado en factorizar funciones de valor global para mejorar la escalabilidad y el rendimiento.
En los últimos años, la investigación sobre métodos de comunicación multiagente ha avanzado significativamente. Una categoría de enfoques apunta a limitar la transmisión de mensajes dentro de la red, utilizando mecanismos de control local para recortar dinámicamente los enlaces de comunicación. Otra categoría se centra en el aprendizaje eficiente para crear mensajes significativos o extraer información valiosa. Estos métodos han empleado diversas técnicas, incluidos mecanismos de atención, redes neuronales gráficas, modelado de compañeros de equipo y esquemas de codificación y decodificación de mensajes personalizados.
Sin embargo, estos enfoques aún enfrentan desafíos a la hora de equilibrar la eficiencia de la comunicación, la escalabilidad y el rendimiento en entornos complejos con múltiples agentes. Cuestiones como la sobrecarga de la comunicación, el poder expresivo limitado de los mensajes discretos y la necesidad de esquemas de agregación de mensajes más sofisticados siguen siendo áreas de investigación y mejora activas.
En este artículo, los investigadores presentan DCMAC (comunicación multiagente personalizada y en función de la demanda)un protocolo robusto diseñado para optimizar el uso de recursos de comunicación limitados, reducir la incertidumbre de entrenamiento y mejorar la colaboración de los agentes en sistemas de aprendizaje de refuerzo de múltiples agentes. Este método de vanguardia presenta un enfoque único en el que los agentes inicialmente transmiten mensajes concisos utilizando recursos de comunicación mínimos. Estos mensajes luego se analizan para comprender las demandas de los compañeros de equipo, lo que permite a los agentes generar mensajes personalizados que influyen en los valores Q de sus compañeros de equipo según la información local y las necesidades percibidas.
DCMAC incorpora un paradigma de entrenamiento innovador basado en el límite superior del rendimiento máximo, alternando entre el modo de entrenamiento y el modo de prueba. En el modo de entrenamiento, se entrena una política ideal utilizando observaciones conjuntas para que sirva como modelo de orientación, lo que ayuda a que la política objetivo converja de manera más eficiente. El modo de prueba emplea una función de pérdida de demanda y un error de diferencia temporal para actualizar los módulos de análisis de demanda y generación de mensajes personalizados.
Este enfoque tiene como objetivo facilitar una comunicación eficiente con recursos limitados, abordando los desafíos clave en sistemas multiagente. La eficacia de DCMAC se demuestra a través de experimentos en diversos entornos, mostrando su capacidad para lograr un rendimiento comparable al de los algoritmos de comunicación sin restricciones y, al mismo tiempo, sobresalir en escenarios con limitaciones de comunicación.
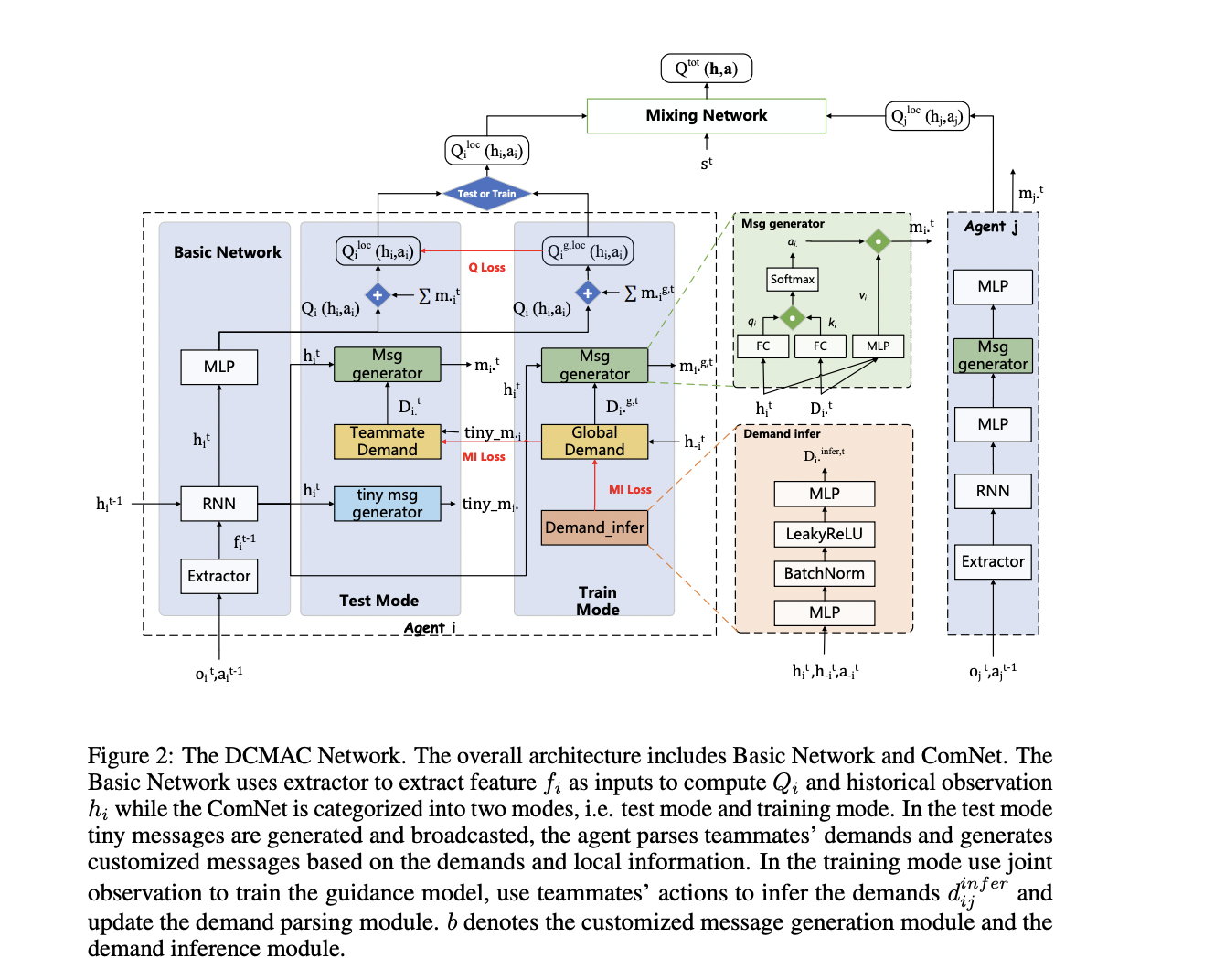
La arquitectura de DCMAC consta de tres módulos principales: generación de mensajes pequeños, análisis de demanda de compañeros de equipo y generación de mensajes personalizados. El proceso comienza con agentes que extraen características de las observaciones utilizando un mecanismo de autoatención para minimizar la información redundante. Estas características luego se procesan a través de un módulo GRU para obtener observaciones históricas.
El módulo de generación de mensajes pequeños crea mensajes de baja dimensión basados en observaciones históricas, que se transmiten periódicamente. El módulo de análisis de demanda interpreta estos mensajes pequeños para comprender las demandas de los compañeros de equipo. Luego, el módulo de generación de mensajes personalizados produce mensajes diseñados para sesgar los valores Q de otros agentes, según las demandas analizadas y las observaciones históricas.
Para optimizar los recursos de comunicación, DCMAC emplea una función de poda de enlaces que utiliza la atención cruzada para calcular las correlaciones entre agentes. Los mensajes se envían solo a los agentes más relevantes en función de las restricciones de comunicación.
DCMAC introduce un paradigma de entrenamiento de límite superior de retorno máximo, que utiliza una política ideal entrenada en observaciones conjuntas como modelo de guía. Este enfoque incluye un módulo de demanda global y un módulo de inferencia de demanda para replicar los efectos de la observación global durante el entrenamiento. El proceso de entrenamiento alterna entre el modo de entrenamiento y el modo de prueba, utilizando información mutua y error de TD para actualizar varios módulos.
Se evaluó el rendimiento de DCMAC en tres entornos de colaboración multiagente conocidos: Hallway, Level-Based Foraging (LBF) y StarCraft II Multi-Agent Challenge (SMAC). Los resultados se compararon con algoritmos de referencia como MAIC, NDQ, QMIX y QPLEX.

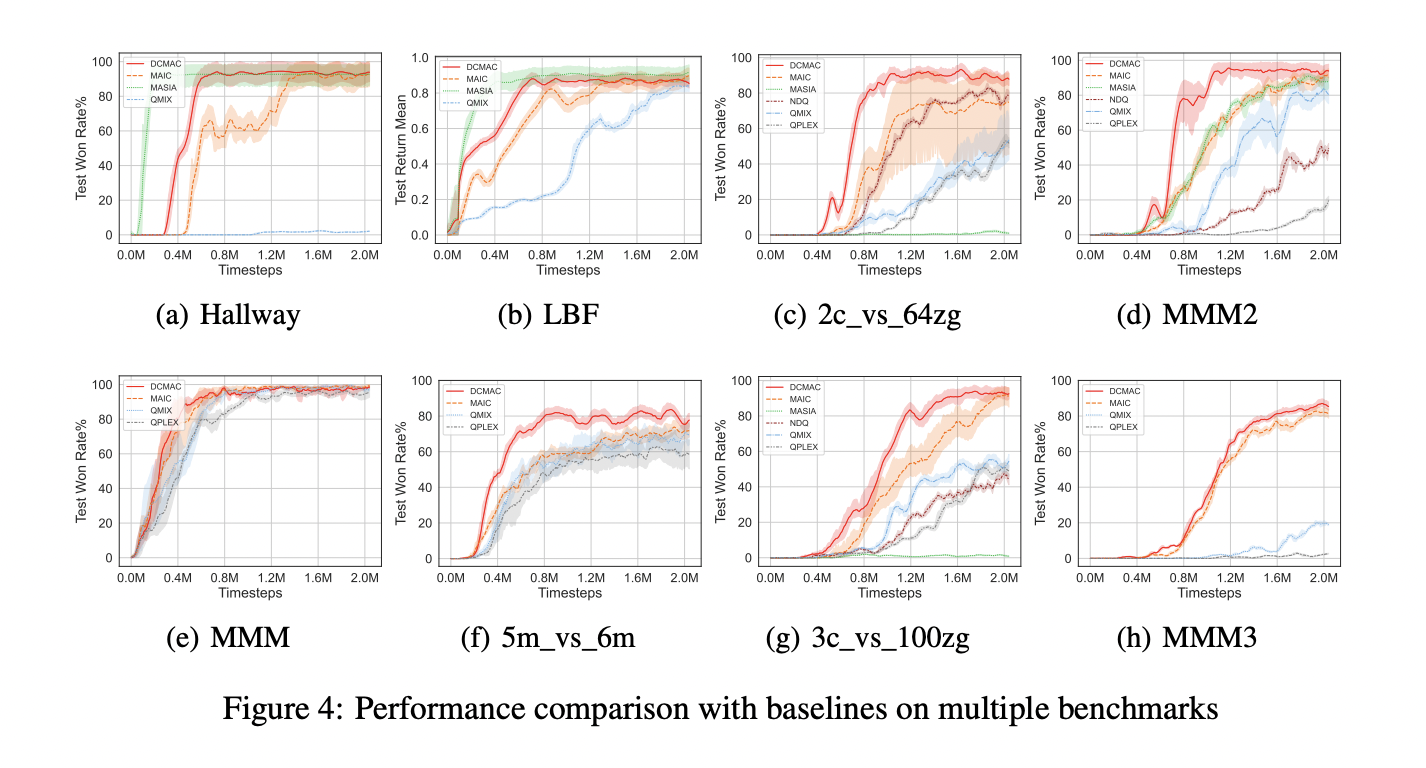
En las pruebas de rendimiento de comunicación, DCMAC mostró resultados superiores en escenarios con grandes espacios de observación, como SMAC. Si bien su rendimiento fue ligeramente inferior al de MASIA en entornos con espacios de observación más pequeños, como Hallway y LBF, aun así mejoró de manera efectiva la colaboración entre agentes. DCMAC superó a otros algoritmos en mapas SMAC difíciles y superdifíciles, lo que demuestra su eficacia en entornos complejos.
El modelo de guía de DCMAC, basado en el paradigma de entrenamiento de límite superior de máximo rendimiento, mostró una excelente convergencia y mayores tasas de éxito en mapas SMAC difíciles y superdifíciles. Este desempeño validó la eficacia del entrenamiento de una política ideal utilizando observaciones conjuntas y la asistencia del módulo de inferencia de demanda.
En entornos con limitaciones de comunicación, DCMAC mantuvo un alto rendimiento con limitaciones de comunicación del 95 % y superó a MAIC incluso con limitaciones más estrictas. Con una restricción de comunicación del 85 %, DCMAC mostró una disminución significativa, pero aun así logró tasas de éxito más altas en el modo de entrenamiento.
Este estudio presenta DCMAC, que introduce un protocolo de comunicación multiagente personalizado que responde a las demandas para mejorar la eficiencia del aprendizaje colaborativo entre múltiples agentes. Supera las limitaciones de los enfoques anteriores al permitir que los agentes transmitan mensajes diminutos y analicen las demandas de los compañeros de equipo, lo que mejora la eficacia de la comunicación. DCMAC incorpora un modelo de guía entrenado en observaciones conjuntas, inspirado en la destilación de conocimientos, para mejorar el proceso de aprendizaje. Experimentos exhaustivos en varios puntos de referencia, incluidos escenarios con limitaciones de comunicación, demuestran la superioridad de DCMAC. El protocolo muestra una fortaleza particular en entornos complejos y con recursos de comunicación limitados, superando los métodos existentes y ofreciendo una solución sólida para la colaboración eficiente en diversas y desafiantes tareas de aprendizaje de refuerzo entre múltiples agentes.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
Asjad es consultor en prácticas en Marktechpost. Está cursando la licenciatura en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en el ámbito de la atención médica.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)