Mejora de modelos lingüísticos de gran tamaño con datos de instrucción diversos: un enfoque de agrupamiento y refinamiento iterativo

Los modelos de lenguaje grandes (LLM) se han convertido en una parte fundamental de la inteligencia artificial, ya que permiten que los sistemas comprendan, generen y respondan al lenguaje humano. Estos modelos se utilizan en varios dominios, incluidos el razonamiento en lenguaje natural, la generación de código y la resolución de problemas. Los LLM suelen entrenarse con grandes cantidades de datos no estructurados de Internet, lo que les permite desarrollar una amplia comprensión del lenguaje. Sin embargo, es necesario realizar ajustes para que sean más específicos de la tarea y se alineen con la intención humana. El ajuste implica el uso de conjuntos de datos de instrucciones que consisten en pares de preguntas y respuestas estructuradas. Este proceso es vital para mejorar la capacidad de los modelos para funcionar con precisión en aplicaciones del mundo real.
La creciente disponibilidad de conjuntos de datos de instrucción presenta un desafío clave para los investigadores: seleccionar de manera eficiente un subconjunto de datos que mejore el entrenamiento del modelo sin agotar los recursos computacionales. Con conjuntos de datos que alcanzan cientos de miles de muestras, es difícil determinar qué subconjunto es óptimo para el entrenamiento. Este problema se agrava por el hecho de que algunos puntos de datos contribuyen de manera más significativa al proceso de aprendizaje que otros. Se requiere algo más que simplemente confiar en la calidad de los datos. En cambio, debe haber un equilibrio entre la calidad de los datos y la diversidad. Priorizar la diversidad en los datos de entrenamiento garantiza que el modelo pueda generalizarse de manera efectiva en varias tareas, evitando el sobreajuste a dominios específicos.
Los métodos actuales de selección de datos suelen centrarse en características locales, como la calidad de los datos. Por ejemplo, los enfoques tradicionales suelen filtrar muestras de baja calidad o instancias duplicadas para evitar entrenar el modelo con datos subóptimos. Sin embargo, este enfoque suele pasar por alto la importancia de la diversidad. Seleccionar solo datos de alta calidad puede dar lugar a modelos que funcionan bien en tareas específicas, pero que necesitan ayuda con una generalización más amplia. Si bien el muestreo de calidad primero se ha utilizado en estudios anteriores, carece de una visión holística de la representatividad general del conjunto de datos. Además, los conjuntos de datos seleccionados manualmente o los filtros basados en la calidad requieren mucho tiempo y es posible que no capturen toda la complejidad de los datos.
Investigadores de la Universidad Northeastern, la Universidad de Stanford, Google Research y Cohere For AI han presentado un innovador método de refinamiento iterativo Para superar estos desafíos, su enfoque enfatiza la selección de datos centrada en la diversidad mediante la agrupación en clústeres de k-medias. Este método garantiza que el subconjunto de datos seleccionado represente el conjunto de datos completo con mayor precisión. Los investigadores proponen un proceso de refinamiento iterativo inspirado en técnicas de aprendizaje activo, que permite al modelo volver a muestrear instancias de clústeres durante el entrenamiento. Este enfoque iterativo garantiza que los clústeres que contienen datos de baja calidad o atípicos se filtren gradualmente, centrándose más en puntos de datos diversos y representativos. El método tiene como objetivo equilibrar la calidad y la diversidad, asegurando que el modelo no se sesgue hacia categorías de datos específicas.
El método introducido Muestreo de calidad k-media (kMQ) y agrupa los puntos de datos en grupos según su similitud. Luego, el algoritmo toma muestras de los datos de cada grupo para formar un subconjunto de datos de entrenamiento. A cada grupo se le asigna un peso de muestreo proporcional a su tamaño, que se ajusta durante el entrenamiento en función de lo bien que el modelo aprende de cada grupo. En esencia, se priorizan los grupos con datos de alta calidad, mientras que a los de menor calidad se les da menos importancia en iteraciones posteriores. El proceso iterativo permite que el modelo refine su aprendizaje a medida que avanza en el entrenamiento, haciendo ajustes según sea necesario. Este método contrasta con los métodos de muestreo fijo tradicionales, que no consideran el comportamiento de aprendizaje del modelo durante el entrenamiento.
El rendimiento de este método se ha probado rigurosamente en múltiples tareas, incluidas las de respuesta a preguntas, razonamiento, matemáticas y generación de código. El equipo de investigación evaluó su modelo en varios conjuntos de datos de referencia, como MMLU (respuesta a preguntas académicas), GSM8k (matemáticas de primaria) y HumanEval (generación de código). Los resultados fueron significativos: el método de muestreo kMQ condujo a una mejora del 7 % en el rendimiento en comparación con la selección aleatoria de datos y una mejora del 3,8 % en comparación con métodos de última generación como Deita y QDIT. En tareas como HellaSwag, que prueba el razonamiento de sentido común, el modelo logró una precisión del 83,3 %, mientras que en GSM8k, el modelo mejoró de 14,5 % a 18,4 % de precisión utilizando el proceso iterativo kMQ. Esto demostró la eficacia del muestreo de diversidad primero para mejorar la generalización del modelo en varias tareas.
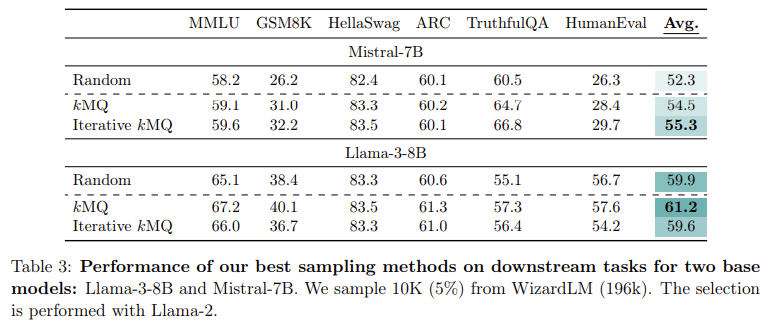
El método de los investigadores superó las técnicas de eficiencia anteriores con estas importantes mejoras de rendimiento. A diferencia de los procesos más complejos que dependen de grandes modelos de lenguaje para puntuar y filtrar los puntos de datos, kMQ logra resultados competitivos sin recursos computacionales costosos. Al utilizar un algoritmo de agrupamiento simple y un refinamiento iterativo, el proceso es escalable y accesible, lo que lo hace adecuado para una variedad de modelos y conjuntos de datos. Esto hace que el método sea particularmente útil para los investigadores que trabajan con recursos limitados y que aún buscan lograr un alto rendimiento en la capacitación de LLM.

En conclusión, esta investigación resuelve uno de los desafíos más importantes en el entrenamiento de modelos lingüísticos de gran tamaño: seleccionar un subconjunto de datos diverso y de alta calidad que maximice el rendimiento en todas las tareas. Al introducir la agrupación en clústeres de k-medias y el refinamiento iterativo, los investigadores han desarrollado un método eficiente que equilibra la diversidad y la calidad en la selección de datos. Su enfoque conduce a mejoras de rendimiento de hasta un 7 % y garantiza que los modelos puedan generalizarse en un amplio espectro de tareas.
Echa un vistazo a la Papel y GitHubTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)