CALM: Asignación de créditos con modelos de lenguaje para la conformación automatizada de recompensas en el aprendizaje por refuerzo

El aprendizaje por refuerzo (RL) es un área fundamental del aprendizaje automático que permite a los agentes aprender de sus interacciones dentro de un entorno al recibir retroalimentación como recompensa. Un desafío importante en el aprendizaje por refuerzo es resolver el problema de asignación de crédito temporal, que se refiere a determinar qué acciones en una secuencia contribuyeron a lograr un resultado deseado. Esto es particularmente difícil cuando la retroalimentación es escasa o se demora, lo que significa que los agentes no saben de inmediato si sus acciones son correctas. En tales situaciones, los agentes deben aprender a correlacionar acciones específicas con resultados, pero la falta de retroalimentación inmediata hace que esta sea una tarea compleja. Los sistemas de aprendizaje por refuerzo a menudo no logran generalizar y escalar de manera efectiva a tareas más complicadas sin mecanismos efectivos para resolver este desafío.
La investigación aborda la dificultad de la asignación de créditos cuando las recompensas se demoran y son escasas. Los agentes de RL a menudo comienzan sin conocimiento previo del entorno y deben navegar por él basándose únicamente en prueba y error. Cuando la retroalimentación es escasa, el agente puede tener dificultades para desarrollar un proceso de toma de decisiones sólido porque no puede discernir qué acciones llevaron a resultados exitosos. Este escenario puede ser particularmente desafiante en entornos complejos con múltiples pasos que conducen a un objetivo, donde solo la secuencia de acciones final produce una recompensa. En muchos casos, los agentes terminan aprendiendo políticas ineficientes o no logran generalizar su comportamiento en diferentes entornos debido a este problema fundamental.
Tradicionalmente, el aprendizaje por refuerzo jerárquico (RL) se ha basado en técnicas como la modelación de recompensas y el aprendizaje por refuerzo jerárquico (HRL) para abordar el problema de la asignación de créditos. La modelación de recompensas es un método en el que se añaden recompensas artificiales para guiar el comportamiento del agente cuando las recompensas naturales son insuficientes. En el RL, las tareas se dividen en subtareas u opciones más simples, y los agentes se entrenan para alcanzar objetivos intermedios. Si bien ambas técnicas pueden ser efectivas, requieren un conocimiento significativo del dominio y la participación humana, lo que dificulta su escalabilidad. En los últimos años, los modelos de lenguaje de gran tamaño (LLM) han demostrado potencial para transferir el conocimiento humano a los sistemas computacionales, ofreciendo nuevas formas de mejorar el proceso de asignación de créditos sin una intervención humana excesiva.
El equipo de investigación del University College de Londres, Google DeepMind y la Universidad de Oxford desarrolló un nuevo enfoque llamado Asignación de créditos con modelos de lenguaje (CALM)CALM aprovecha el poder de los LLM para descomponer las tareas en subobjetivos más pequeños y evaluar el progreso del agente hacia estos objetivos. A diferencia de los métodos tradicionales que requieren recompensas extensivas diseñadas por humanos, CALM automatiza este proceso al permitir que el LLM determine subobjetivos y proporcione señales de recompensa auxiliares. La técnica reduce la participación humana en el diseño de sistemas de RL, lo que facilita la escalabilidad a diferentes entornos. Los investigadores afirman que este método puede manejar configuraciones de cero disparos, lo que significa que el LLM puede evaluar acciones sin requerir ajustes finos o ejemplos previos específicos para la tarea.
CALM utiliza LLM para evaluar si se logran subobjetivos específicos durante una tarea. Por ejemplo, en el entorno MiniHack utilizado en el estudio, los agentes tienen la tarea de recoger una llave y abrir una puerta para recibir una recompensa. CALM divide esta tarea en subobjetivos manejables, como “navegar hasta la llave”, “recoger la llave” y “abrir la puerta”. Cada vez que se completa uno de estos subobjetivos, CALM proporciona una recompensa auxiliar al agente RL, guiándolo hacia la finalización de la tarea final. Este sistema reduce la necesidad de funciones de recompensa diseñadas manualmente, que a menudo requieren mucho tiempo y son específicas del dominio. En cambio, el LLM utiliza su conocimiento previo para dar forma de manera efectiva al comportamiento del agente.
Los experimentos de los investigadores evaluaron CALM utilizando un conjunto de datos de 256 demostraciones anotadas por humanos de MiniHack, un entorno de juego que desafía a los agentes a resolver tareas en un mundo similar a una cuadrícula. Los resultados mostraron que los LLM podían asignar crédito con éxito en entornos de cero disparos, lo que significa que el modelo no requirió ejemplos previos ni ajustes. En particular, el LLM podía reconocer cuándo se habían logrado los subobjetivos, lo que proporcionaba una guía útil al agente RL. El estudio descubrió que el LLM reconocía con precisión los subobjetivos y los alineaba con las anotaciones humanas, logrando una puntuación F1 de 0,74. El rendimiento del LLM mejoró significativamente cuando se utilizaron observaciones más enfocadas, como imágenes recortadas que muestran una vista de 9×9 alrededor del agente. Esto sugiere que los LLM pueden ser una herramienta valiosa para automatizar la asignación de créditos, particularmente en entornos donde las recompensas naturales son escasas o demoradas.
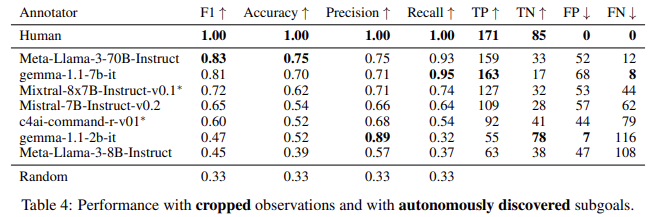
Los investigadores también informaron que el rendimiento de CALM era competitivo con el de los anotadores humanos a la hora de identificar la finalización exitosa de subobjetivos. En algunos casos, el LLM alcanzó una tasa de precisión de 0,73 al detectar cuándo un agente había completado un subobjetivo, y las recompensas auxiliares proporcionadas por CALM ayudaron al agente a aprender de manera más eficiente. El equipo también comparó el rendimiento de CALM con modelos existentes como Meta-Llama-3 y descubrió que CALM tenía un buen rendimiento en varias métricas, incluidas la recuperación y la precisión, con puntuaciones de precisión que oscilaban entre 0,60 y 0,97, según el modelo y la tarea.

En conclusión, la investigación demuestra que CALM puede abordar eficazmente el problema de asignación de créditos en RL aprovechando los LLM. CALM reduce la necesidad de una amplia participación humana en el diseño de sistemas RL al dividir las tareas en subobjetivos y automatizar la conformación de recompensas. Los experimentos indican que los LLM pueden proporcionar retroalimentación precisa a los agentes RL, mejorando su capacidad de aprendizaje en entornos con recompensas escasas. Este enfoque puede mejorar el rendimiento de RL en varias aplicaciones, lo que lo convierte en una vía prometedora para la investigación y el desarrollo futuros. El estudio destaca el potencial de los LLM para generalizarse en todas las tareas, lo que hace que los sistemas RL sean más escalables y eficientes en escenarios del mundo real.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)