RetrievalAttention: un enfoque de aprendizaje automático sin entrenamiento para acelerar el cálculo de la atención y reducir el consumo de memoria de la GPU

Los modelos de lenguaje de gran tamaño (LLM) han logrado avances significativos en el procesamiento de contextos extensos, y algunos modelos son capaces de manejar hasta 10 millones de tokens. Sin embargo, este avance plantea desafíos en la eficiencia de la inferencia debido a la complejidad cuadrática del cálculo de la atención. Si bien el almacenamiento en caché KV se ha adoptado ampliamente para evitar cálculos redundantes, introduce requisitos sustanciales de memoria de GPU y una mayor latencia de inferencia para contextos largos. El modelo Llama-2-7B, por ejemplo, requiere aproximadamente 500 GB por millón de tokens en formato FP16. Estos problemas resaltan la necesidad crítica de reducir los costos de acceso y almacenamiento de tokens para mejorar la eficiencia de la inferencia. La solución a estos desafíos radica en utilizar la escasez dinámica inherente al mecanismo de atención, donde cada vector de consulta interactúa significativamente solo con un subconjunto limitado de vectores de clave y valor.
Los intentos existentes para acelerar la inferencia LLM de contexto largo se han centrado en comprimir el tamaño de la caché KV mediante el uso de escasez de atención. Sin embargo, estos métodos a menudo resultan en caídas significativas de precisión debido a la naturaleza dinámica de la escasez de atención. Algunos enfoques, como FlexGen y Lamina, descargan la caché KV en la memoria de la CPU, pero enfrentan desafíos con un cálculo de atención completa lento y costoso. Otros métodos, como Quest e InfLLM, dividen la caché KV en bloques y seleccionan vectores de clave representativos, pero su efectividad depende en gran medida de la precisión de estos representantes. SparQ, InfiniGen y LoKi intentan aproximarse a las claves top-k más relevantes reduciendo las dimensiones de la cabeza.
Investigadores de Microsoft Research, la Universidad Jiao Tong de Shanghai y la Universidad de Fudan presentan RecuperaciónAtenciónun método innovador diseñado para acelerar la generación de LLM de contexto largo. Emplea atención dispersa dinámica durante la generación de tokens, lo que permite que los tokens más críticos surjan de datos de contexto extensos. Para abordar el desafío de la distribución fuera de distribución (OOD), RetrievalAttention presenta un índice vectorial diseñado específicamente para el mecanismo de atención, que se centra en la distribución de consultas en lugar de las similitudes clave. Este enfoque permite el recorrido de solo el 1% al 3% de los vectores clave, lo que identifica de manera efectiva los tokens más relevantes para obtener puntajes de atención precisos y resultados de inferencia. RetrievalAttention también optimiza el consumo de memoria de la GPU al retener una pequeña cantidad de vectores KV en la memoria de la GPU siguiendo patrones estáticos, mientras descarga la mayoría en la memoria de la CPU para la construcción del índice. Durante la generación de tokens, recupera de manera eficiente tokens críticos utilizando índices vectoriales en la CPU y fusiona resultados de atención parcial tanto de la CPU como de la GPU. Esta estrategia permite que RetrievalAttention realice el cálculo de la atención con una latencia reducida y un consumo mínimo de memoria de la GPU.
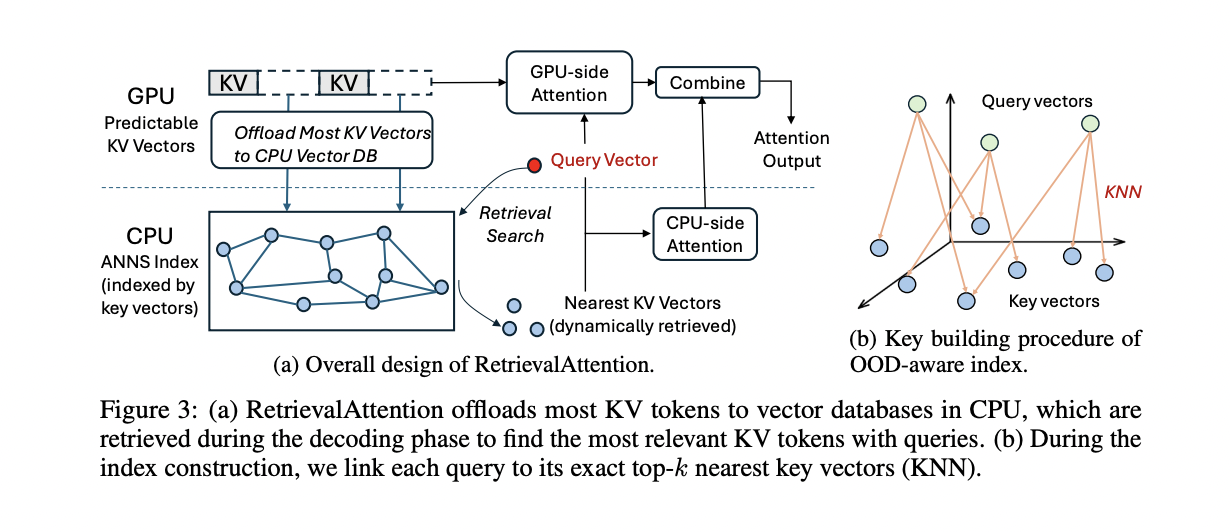
RetrievalAttention emplea una estrategia de co-ejecución CPU-GPU para acelerar el cálculo de la atención para la inferencia LLM de contexto largo. El método descompone el cálculo de la atención en dos conjuntos disjuntos de vectores de caché KV: los predecibles en la GPU y los dinámicos en la CPU. Utiliza patrones observados en la fase de prellenado para predecir vectores KV activados consistentemente durante la generación de tokens, y los conserva en la caché de la GPU. La implementación actual utiliza tokens iniciales fijos y la última ventana deslizante del contexto como patrón estático, similar a StreamingLLM. Para el cálculo del lado de la CPU, RetrievalAttention crea un índice de búsqueda de vectores que tiene en cuenta la atención para recuperar de manera eficiente los vectores KV relevantes. Este índice se construye utilizando conexiones KNN de vectores de consulta a vectores clave, que luego se proyectan sobre vectores clave para agilizar el proceso de búsqueda. Este enfoque permite escanear solo el 1-3% de los vectores clave para lograr una alta recuperación, lo que reduce significativamente la latencia de búsqueda del índice. Para minimizar la transferencia de datos a través de la interfaz PCIe, RetrievalAttention calcula de forma independiente los resultados de atención de los componentes de CPU y GPU antes de combinarlos, inspirado en FastAttention.
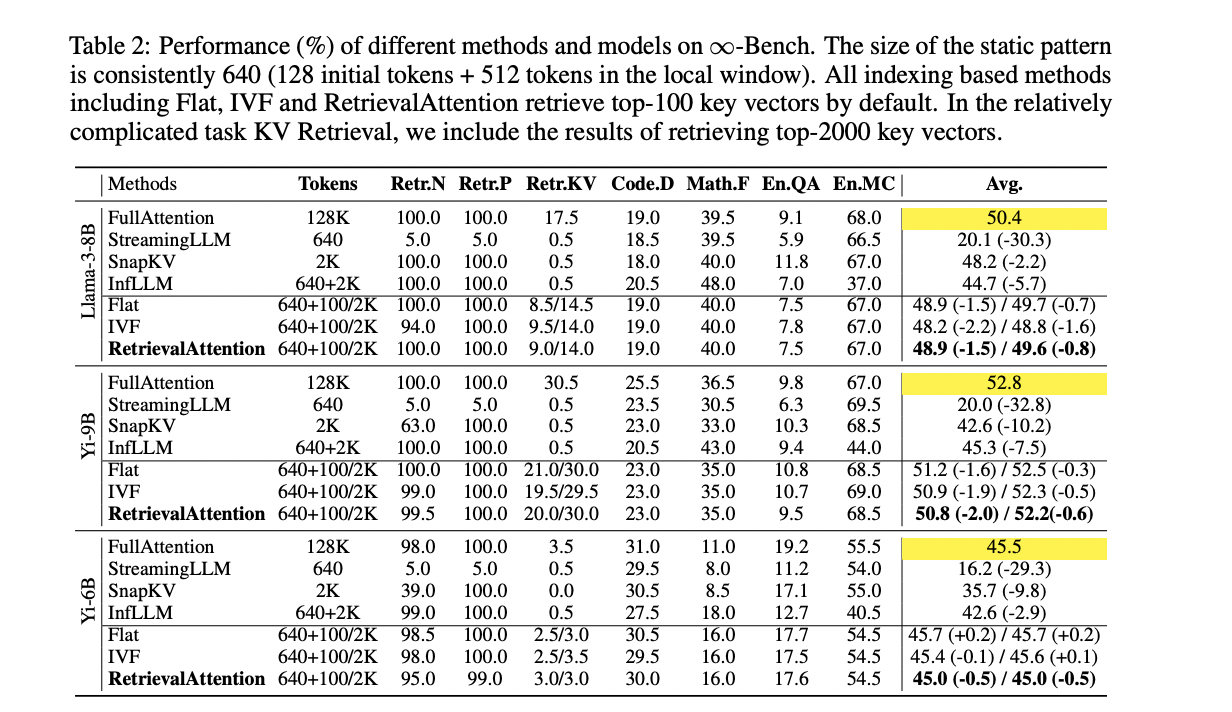
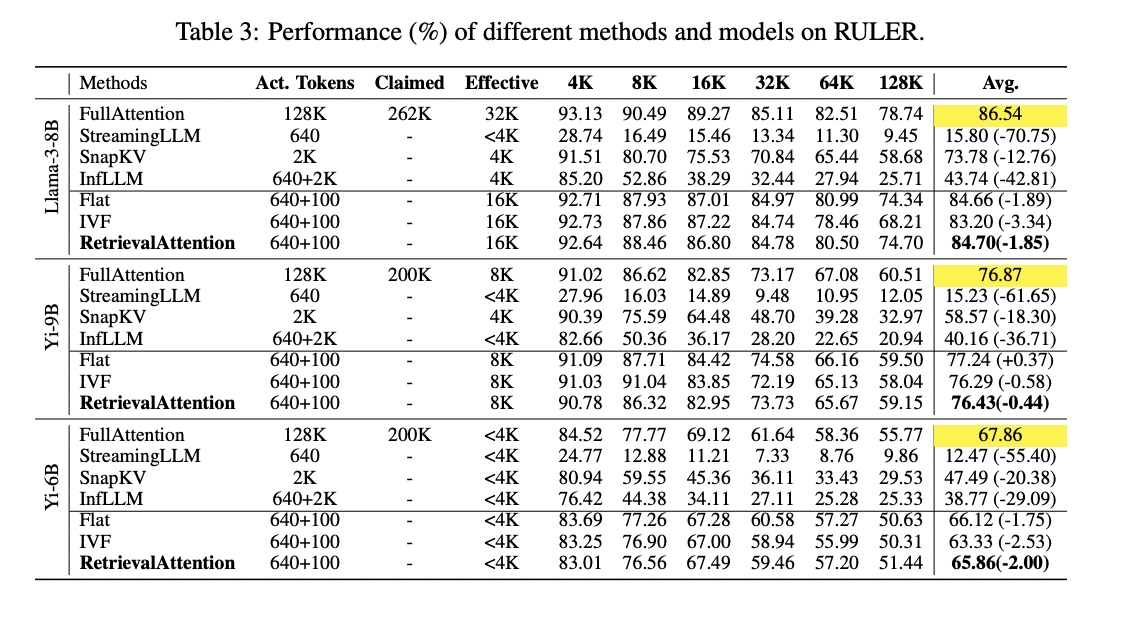
RetrievalAttention demuestra un rendimiento superior tanto en precisión como en eficiencia en comparación con los métodos existentes. Logra una precisión comparable a la atención completa al tiempo que reduce significativamente los costos computacionales. En tareas complejas como la recuperación de KV, RetrievalAttention supera a los métodos estáticos como StreamingLLM y SnapKV, que carecen de capacidades de recuperación de tokens dinámicos. También supera a InfLLM, que tiene dificultades con la precisión debido a los vectores representativos de baja calidad. La capacidad de RetrievalAttention para identificar con precisión los vectores clave relevantes le permite mantener una alta precisión de la tarea en varias longitudes de contexto, desde tokens de 4K a 128K. En la tarea de buscar una aguja en un pajar, se centra de manera efectiva en la información crítica independientemente de la posición dentro de la ventana de contexto. Con respecto a la latencia, RetrievalAttention muestra mejoras significativas con respecto a la atención completa y otros métodos. Logra una reducción de latencia de 4,9× y 1,98× en comparación con los índices Flat e IVF respectivamente para el contexto de 128K, mientras que escanea solo el 1-3% de los vectores. Esta combinación de alta precisión y baja latencia demuestra la eficacia de RetrievalAttention en el manejo de tareas complejas y dinámicas con contextos largos.
Este estudio presenta RecuperaciónAtenciónuna solución innovadora para acelerar la inferencia LLM de contexto largo al descargar la mayoría de los vectores KV a la memoria de la CPU y emplear atención dispersa dinámica a través de la búsqueda de vectores. El método aborda las diferencias de distribución entre los vectores de consulta y clave, utilizando un enfoque consciente de la atención para identificar de manera eficiente los tokens críticos para la generación de modelos. Los resultados experimentales demuestran la eficacia de RetrievalAttention, logrando una aceleración de decodificación de 4,9× y 1,98× en comparación con los métodos KNN exactos y ANNS tradicionales, respectivamente, en una sola GPU RTX4090 con un contexto de 128K tokens. RetrievalAttention es el primer sistema que admite la ejecución de LLM de nivel 8B con 128K tokens en una sola GPU 4090 (24 GB), manteniendo una latencia aceptable y preservando la precisión del modelo. Este avance mejora significativamente la eficiencia y la accesibilidad de los modelos de lenguaje grandes para el procesamiento de contexto extenso.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asjad es consultor en prácticas en Marktechpost. Está cursando la licenciatura en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en el ámbito de la atención médica.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)