Nvidia AI lanza Llama-3.1-Nemotron-51B: un nuevo LLM que permite ejecutar cargas de trabajo 4 veces más grandes en una sola GPU durante la inferencia

Nvidia presentó su última oferta de modelo de lenguaje grande (LLM), el Llama-3.1-Nemotron-51BEste modelo, basado en Llama-3.1-70B de Meta, se ha perfeccionado con técnicas avanzadas de búsqueda de arquitectura neuronal (NAS), lo que ha dado como resultado un gran avance tanto en rendimiento como en eficiencia. Diseñado para adaptarse a una única GPU Nvidia H100, el modelo reduce significativamente el consumo de memoria, la complejidad computacional y los costos asociados con la ejecución de modelos tan grandes. Marca un hito importante en los esfuerzos continuos de Nvidia por optimizar los modelos de IA a gran escala para aplicaciones del mundo real.
Los orígenes de Llama-3.1-Nemotron-51B
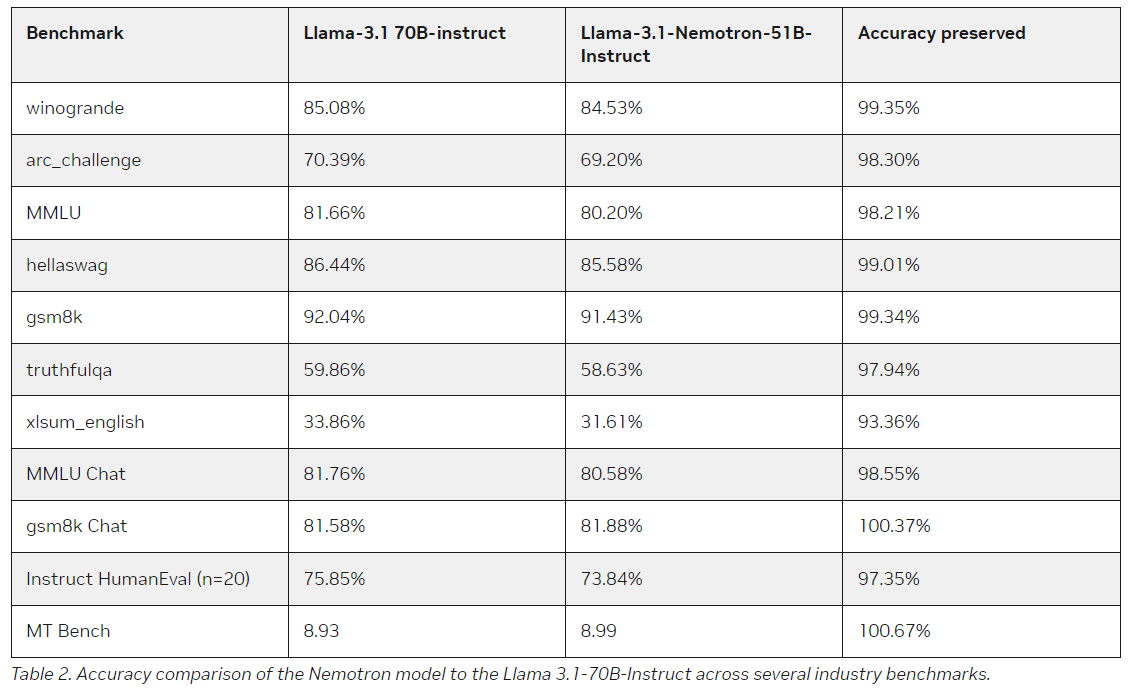
Llama-3.1-Nemotron-51B es un derivado del Llama-3.1-70B de Meta, que se lanzó en julio de 2024. Si bien el modelo de Meta ya había establecido un alto nivel de rendimiento, Nvidia buscó ir más allá centrándose en la eficiencia. Al emplear NAS, los investigadores de Nvidia han creado un modelo que ofrece un rendimiento similar, si no mejor, y reduce significativamente la demanda de recursos. En cuanto a la potencia computacional bruta, el Llama-3.1-Nemotron-51B ofrece una inferencia 2,2 veces más rápida que su predecesor, manteniendo un nivel de precisión comparable.
Avances en eficiencia y rendimiento
Uno de los desafíos clave en el desarrollo de LLM es equilibrar la precisión con la eficiencia computacional. Muchos modelos a gran escala ofrecen resultados de vanguardia, pero a costa de enormes recursos de hardware y energía, lo que limita su aplicabilidad. El nuevo modelo de Nvidia logra un delicado equilibrio entre estos dos factores en pugna.
Llama-3.1-Nemotron-51B logra un equilibrio entre precisión y eficiencia impresionante, ya que reduce el ancho de banda de la memoria, disminuye la cantidad de operaciones de punto flotante por segundo (FLOP) y disminuye el uso general de la memoria sin comprometer la capacidad del modelo para realizar tareas complejas como razonamiento, resumen y generación de lenguaje. Nvidia ha comprimido el modelo hasta el punto en que puede ejecutar cargas de trabajo más grandes que nunca en una sola GPU H100, lo que abre muchas posibilidades nuevas tanto para desarrolladores como para empresas.
Gestión de la carga de trabajo mejorada y rentabilidad
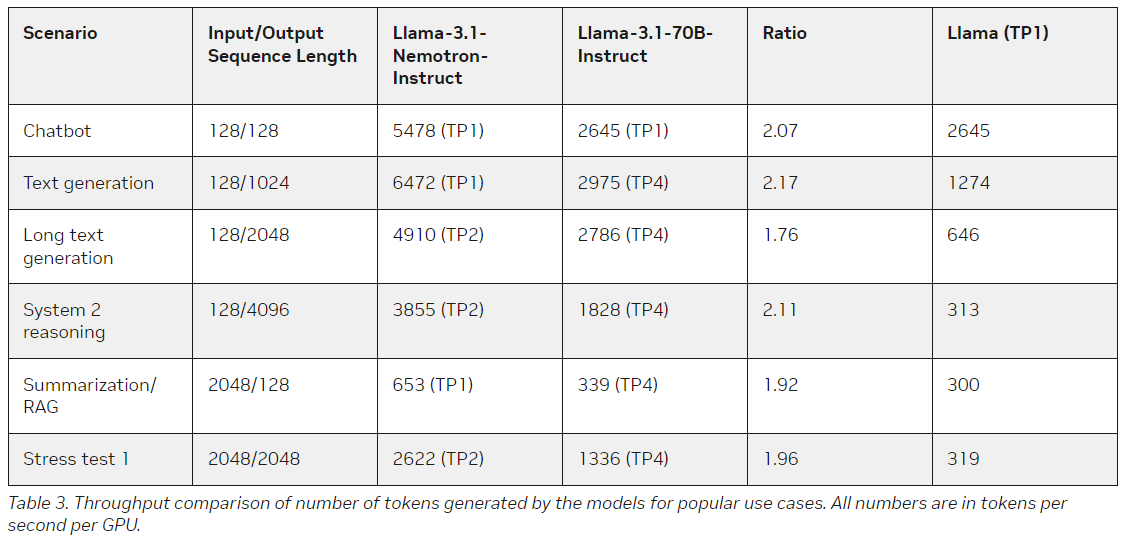
Una característica destacada del Llama-3.1-Nemotron-51B es su capacidad para gestionar cargas de trabajo más grandes en una sola GPU. Este modelo permite a los desarrolladores implementar LLM de alto rendimiento en entornos más rentables, ejecutando tareas que antes habrían requerido varias GPU en una sola unidad H100.
Por ejemplo, el modelo puede manejar cargas de trabajo cuatro veces mayores durante la inferencia que el modelo de referencia Llama-3.1-70B. También permite un rendimiento más rápido: Nvidia informa que su rendimiento es 1,44 veces mejor en áreas clave que otros modelos. La eficiencia de Llama-3.1-Nemotron-51B se debe a un enfoque innovador de la arquitectura, que se centra en reducir la redundancia en los procesos computacionales y, al mismo tiempo, preservar la capacidad del modelo para ejecutar tareas lingüísticas complejas con alta precisión.
Optimización de la arquitectura: la clave del éxito
El éxito del Llama-3.1-Nemotron-51B se debe en gran medida a un enfoque novedoso para optimizar la arquitectura. Tradicionalmente, los LLM se construyen utilizando bloques idénticos, que se repiten a lo largo del modelo. Si bien esto simplifica el proceso de construcción, introduce ineficiencias, en particular en lo que respecta a la memoria y los costos computacionales.
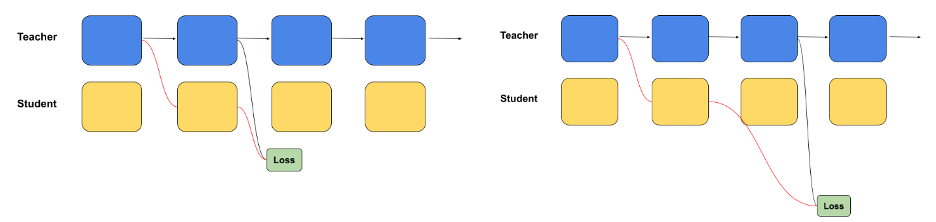
Nvidia abordó estos problemas empleando técnicas NAS que optimizan el modelo para la inferencia. El equipo ha utilizado un proceso de destilación de bloques, en el que se entrenan modelos de estudiantes más pequeños y eficientes para imitar la funcionalidad del modelo de profesor más grande. Al refinar estos modelos de estudiantes y evaluar su rendimiento, Nvidia ha producido una versión de Llama-3.1 que ofrece niveles similares de precisión y, al mismo tiempo, reduce drásticamente los requisitos de recursos.
El proceso de destilación de bloques permite a Nvidia explorar diferentes combinaciones de atención y redes de retroalimentación (FFN) dentro del modelo, creando configuraciones alternativas que priorizan la velocidad o la precisión, según los requisitos específicos de la tarea. Esta flexibilidad convierte a Llama-3.1-Nemotron-51B en una herramienta poderosa para diversas industrias que necesitan implementar IA a escala, ya sea en entornos de nube, centros de datos o incluso configuraciones de computación de borde.
El algoritmo del rompecabezas y la destilación del conocimiento
El algoritmo Puzzle es otro componente fundamental que distingue a Llama-3.1-Nemotron-51B de otros modelos. Este algoritmo puntúa cada bloque potencial dentro del modelo y determina qué configuraciones ofrecerán el mejor equilibrio entre velocidad y precisión. Al utilizar técnicas de destilación de conocimientos, Nvidia ha reducido la brecha de precisión entre el modelo de referencia (Llama-3.1-70B) y el Nemotron-51B, al mismo tiempo que reduce significativamente los costos de capacitación.
A través de este proceso, Nvidia ha creado un modelo que opera en la frontera eficiente del desarrollo de modelos de IA, ampliando los límites de lo que se puede lograr con una sola GPU. Al garantizar que cada bloque dentro del modelo sea lo más eficiente posible, Nvidia ha creado un modelo que supera a muchos de sus pares en precisión y rendimiento.
El compromiso de Nvidia con soluciones de IA rentables
El costo siempre ha sido una barrera importante para la adopción generalizada de modelos de lenguaje de gran tamaño. Si bien el rendimiento de estos modelos es innegable, sus costos de inferencia han limitado su uso solo a las organizaciones con más recursos. Llama-3.1-Nemotron-51B de Nvidia aborda este desafío de frente, ofreciendo un modelo que funciona a un alto nivel y que busca la rentabilidad.
Los requisitos computacionales y de memoria reducidos del modelo lo hacen mucho más accesible para organizaciones más pequeñas y desarrolladores que podrían no tener los recursos para ejecutar modelos más grandes. Nvidia también ha simplificado el proceso de implementación, empaquetando el modelo como parte de su Nvidia Inference Microservice (NIM), que utiliza motores TensorRT-LLM para inferencia de alto rendimiento. Este sistema está diseñado para implementarse fácilmente en varios entornos, desde entornos de nube hasta dispositivos de borde, y puede escalar según la demanda.
Aplicaciones futuras e implicaciones
El lanzamiento de Llama-3.1-Nemotron-51B tiene implicaciones de largo alcance para el futuro de la IA generativa y los LLM. Al hacer que los modelos de alto rendimiento sean más accesibles y rentables, Nvidia ha abierto la puerta a una gama más amplia de industrias para aprovechar estas tecnologías. El menor costo de la inferencia también significa que los LLM ahora se pueden implementar en áreas que antes eran demasiado costosas para justificarlas, como aplicaciones en tiempo real, chatbots de servicio al cliente y más.
La flexibilidad del enfoque NAS utilizado en el desarrollo del modelo significa que Nvidia puede seguir perfeccionando y optimizando la arquitectura para diferentes configuraciones de hardware y casos de uso. Ya sea que un desarrollador necesite un modelo optimizado para la velocidad o la precisión, Llama-3.1-Nemotron-51B de Nvidia proporciona una base que se puede adaptar para satisfacer diversos requisitos.
Conclusión
Llama-3.1-Nemotron-51B de Nvidia es un lanzamiento que cambia las reglas del juego en el mundo de la IA. Al centrarse en el rendimiento y la eficiencia, Nvidia ha creado un modelo que no solo rivaliza con los mejores de la industria, sino que también establece un nuevo estándar de rentabilidad y accesibilidad. El uso de técnicas de NAS y destilación de bloques ha permitido a Nvidia superar las limitaciones tradicionales de los LLM, lo que hace posible implementar estos modelos en una sola GPU manteniendo una alta precisión. A medida que la IA generativa continúa evolucionando, modelos como Llama-3.1-Nemotron-51B desempeñarán un papel crucial en la configuración del futuro de la industria, lo que permitirá que más organizaciones aprovechen el poder de la IA en sus operaciones diarias. Ya sea para el procesamiento de datos a gran escala, la generación de lenguaje en tiempo real o tareas de razonamiento avanzado, la última oferta de Nvidia promete ser una herramienta valiosa para desarrolladores y empresas.
Echa un vistazo a la Modelo y BlogTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc. Como ingeniero y emprendedor visionario, Asif está comprometido con aprovechar el potencial de la inteligencia artificial para el bien social. Su iniciativa más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad de noticias sobre aprendizaje automático y aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)