Iteración del pensamiento: un marco de IA para mejorar las respuestas de LLM mediante la generación de indicaciones que estimulen la “reflexión”

Los modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés) han revolucionado el procesamiento del lenguaje natural, permitiendo que los sistemas de IA realicen una amplia gama de tareas con una habilidad notable. Sin embargo, los investigadores enfrentan desafíos significativos para optimizar el desempeño de los LLM, particularmente en las interacciones entre humanos y LLM. Una observación crítica revela que la calidad de las respuestas de los LLM tiende a mejorar con las indicaciones repetidas y la retroalimentación del usuario. Las metodologías actuales a menudo se basan en indicaciones ingenuas, lo que conduce a errores de calibración y resultados subóptimos. Esto presenta un problema crucial: desarrollar estrategias de indicaciones más sofisticadas que puedan mejorar significativamente la precisión y confiabilidad de los resultados de los LLM, maximizando así su potencial en diversas aplicaciones.
Los investigadores han intentado superar los desafíos que supone optimizar el rendimiento de los estudiantes de maestría en derecho mediante diversas estrategias de estímulo. El método de entrada-salida (IO) representa el enfoque más básico, ya que utiliza un mecanismo de entrada-salida directo sin razonamiento intermedio. Sin embargo, este método suele resultar insuficiente en tareas complejas que requieren una comprensión matizada. El estímulo de la cadena de pensamiento (CoT) surgió como un avance, al introducir una única vía de razonamiento lineal. Este enfoque anima a los estudiantes de maestría en derecho a articular pasos de razonamiento intermedios, lo que conduce a un mejor rendimiento en tareas complejas. Sobre la base de esto, los métodos de árbol de pensamiento (ToT) ampliaron el concepto al explorar múltiples vías de razonamiento en paralelo, formando una estructura de ramificación para optimizar los resultados. Este enfoque ha demostrado una eficacia particular en tareas exploratorias como la resolución de acertijos. Además, algunos otros marcos, como el de autorrefinamiento y autoverificación, permiten a los estudiantes de maestría en derecho criticar y refinar sus resultados de forma iterativa. Sin embargo, estos métodos todavía dependen de estímulos estáticos o semiestáticos, lo que limita su adaptabilidad a contextos en evolución. A pesar de estos avances, los enfoques actuales tienen dificultades para utilizar plenamente la base de conocimientos interna del LLM y adaptarse dinámicamente a cada contexto único de consulta y respuesta.
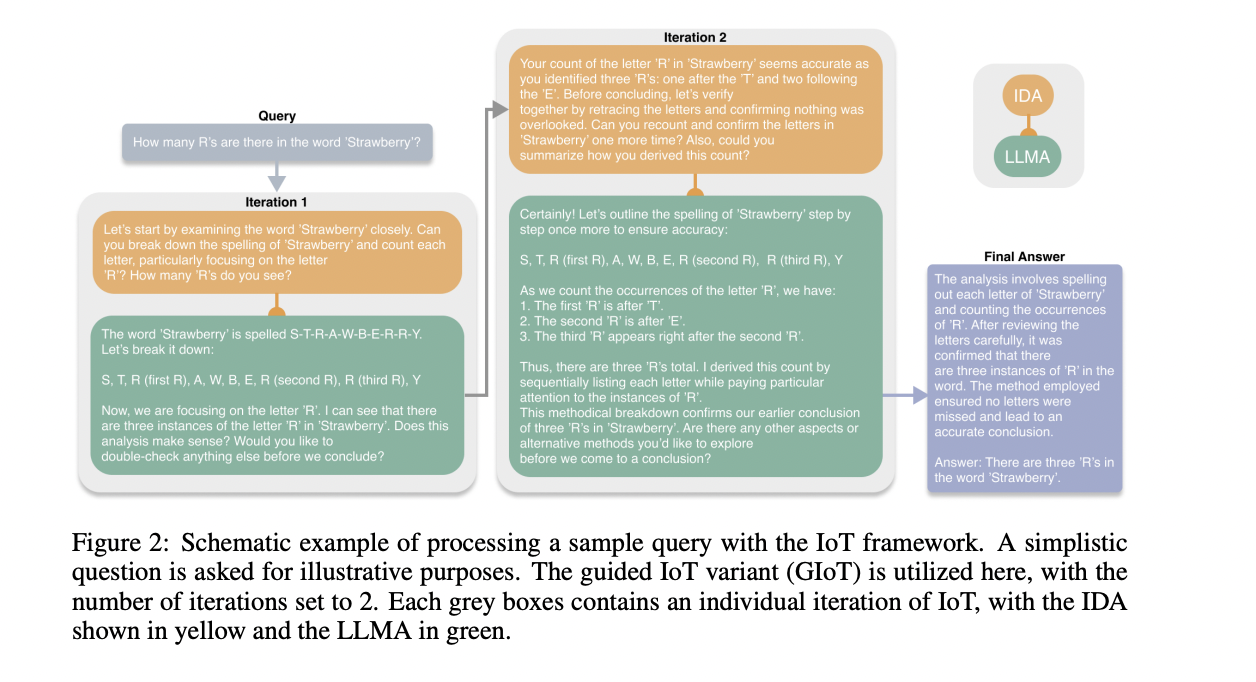
Investigadores de Agnostiq Inc. y la Universidad de Toronto presentan el Iteración del pensamiento (IoT) El marco de IoT es un enfoque autónomo, iterativo y adaptativo para el razonamiento LLM sin retroalimentación humana. A diferencia de los marcos estáticos y semiestáticos, IoT utiliza un agente de diálogo interno (IDA) para ajustar y refinar su ruta de razonamiento durante cada iteración. Esto permite la exploración adaptativa a través de diferentes árboles de razonamiento, lo que fomenta un proceso de generación de respuestas más flexible y consciente del contexto. Además, el marco de IoT central consta de tres componentes principales: el IDA, el agente LLM y el bucle de solicitud iterativa. El IDA funciona como una guía, generando dinámicamente solicitudes sensibles al contexto basadas en la consulta original del usuario y la respuesta anterior del LLM. El LLMA incorpora las capacidades de razonamiento centrales de un LLM, procesando las solicitudes generadas dinámicamente del IDA. El bucle de solicitud iterativa facilita una interacción de ida y vuelta entre el IDA y el LLMA, mejorando continuamente la calidad de las respuestas sin aportes externos.
El marco de IoT se implementa a través de dos variantes: la iteración autónoma del pensamiento (AIoT) y la iteración guiada del pensamiento (GIoT). La AIoT permite que el agente LLM decida de forma autónoma cuándo ha generado una respuesta satisfactoria, lo que puede conducir a una evaluación más rápida, pero con el riesgo de paradas prematuras en consultas complejas. GIoT exige un número fijo de iteraciones, con el objetivo de una exploración integral de los caminos de razonamiento a costa de recursos computacionales adicionales. Ambas variantes utilizan los componentes centrales de IoT: el agente de diálogo interno, el agente LLM y el bucle de solicitud iterativa. Implementado como una biblioteca de Python con Pydantic para esquemas de salida, IoT permite la exploración adaptativa a través de diferentes árboles de razonamiento. La elección entre AIoT y GIoT permite equilibrar la profundidad de exploración y la eficiencia computacional en función de los requisitos de la tarea.
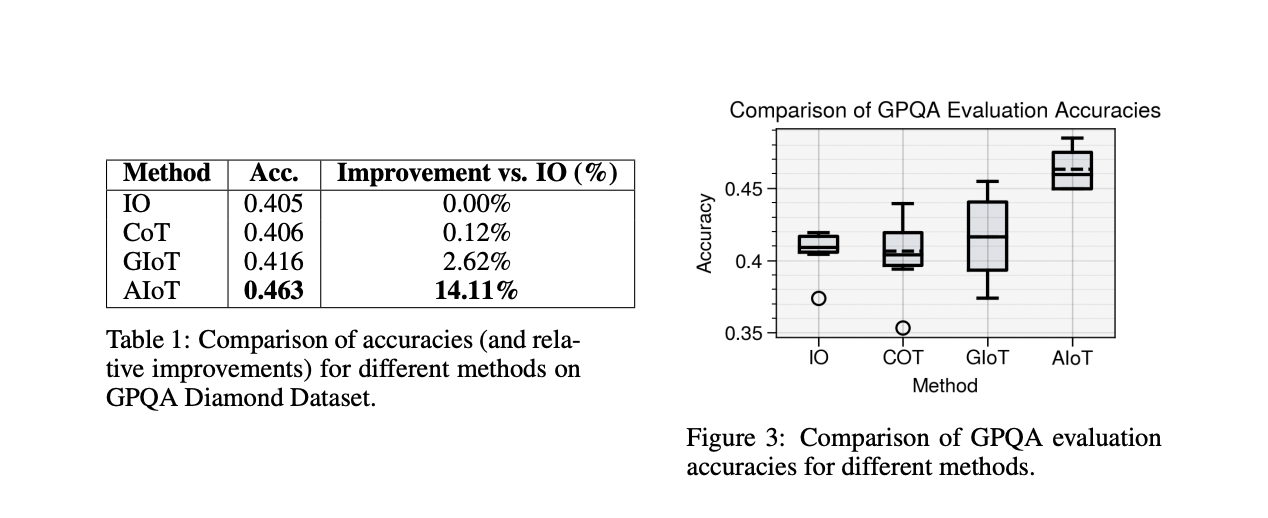
El marco de IoT demuestra mejoras significativas en varias tareas de razonamiento. En el conjunto de datos GPQA Diamond, AIoT logró una mejora de precisión del 14,11 % con respecto al método de entrada-salida de referencia, superando a CoT y GIoT. Para tareas de resolución de problemas exploratorios como Game of 24 y Mini Crosswords, GIoT mostró un rendimiento superior, con mejoras del 266,4 % y el 90,6 % respectivamente con respecto a CoT. En tareas de razonamiento multicontextual con el conjunto de datos HotpotQA-Hard, AIoT superó a CoT e incluso superó al marco AgentLite, logrando un F1 más alto de 0,699 y una coincidencia exacta de 0,53. Estos resultados destacan la eficacia de IoT para adaptarse a diferentes contextos de razonamiento, desde tareas de conocimiento profundo hasta respuestas a preguntas de múltiples saltos, lo que demuestra su potencial como un marco de razonamiento versátil y poderoso para modelos de lenguaje grandes.
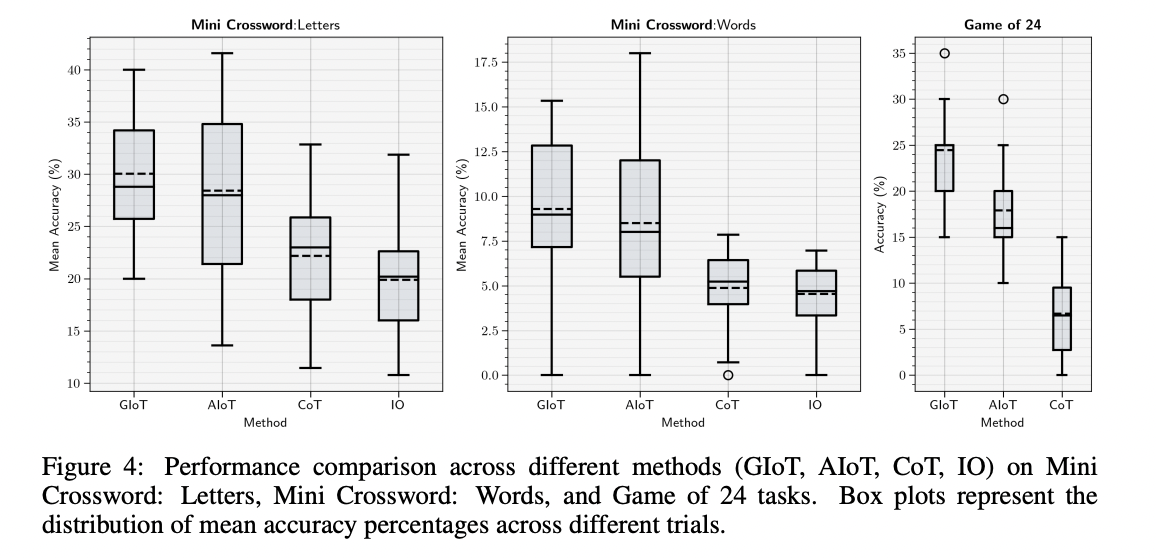
El marco de IoT presenta un enfoque único para tareas de razonamiento complejas utilizando modelos de lenguaje grandes. IoT demuestra mejoras significativas en varias tareas desafiantes al emplear un IIDA que conversa iterativamente con un agente LLM. Se probaron dos variantes del marco, AIoT y GIoT, en diversos problemas, incluidos rompecabezas (Juego de 24, Mini Crucigramas) y cuestionarios complejos (GPQA, HotpotQA). GIoT, que realiza un número fijo de iteraciones, se destacó en el Juego de 24, mientras que AIoT, con su terminación autodeterminada, mostró un rendimiento superior en GPQA. Ambas variantes superaron al marco CoT en todas las tareas comparadas. En particular, en la tarea HotpotQA multicontexto, IoT superó al marco jerárquico AgentLite, logrando una mejora de aproximadamente el 35 % en la puntuación F1 y del 44 % en la puntuación Exact Match. Estos resultados subrayan la capacidad de la IoT para introducir dinamismo productivo en marcos de agentes de baja complejidad, lo que marca un avance significativo en las capacidades de razonamiento de LLM.
Echa un vistazo a la PapelTodo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Arriba!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)
Asjad es consultor en prácticas en Marktechpost. Está cursando la licenciatura en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en el ámbito de la atención médica.
⏩ ⏩ SEMINARIO WEB GRATUITO SOBRE IA: ‘SAM 2 para video: cómo optimizar sus datos’ (miércoles 25 de septiembre, 4:00 a. m. a 4:45 a. m. EST)