Un estudio completo de modelos de lenguajes pequeños: arquitecturas, conjuntos de datos y algoritmos de entrenamiento

Los modelos de lenguaje pequeño (SLM) se han convertido en un punto focal en el procesamiento del lenguaje natural (NLP) debido a su potencial para llevar inteligencia artificial de alta calidad a los dispositivos cotidianos. A diferencia de los grandes modelos de lenguaje (LLM) que operan dentro de centros de datos en la nube y exigen importantes recursos computacionales, los SLM apuntan a democratizar la inteligencia artificial haciéndola accesible en dispositivos más pequeños y con recursos limitados, como teléfonos inteligentes, tabletas y dispositivos portátiles. Estos modelos suelen oscilar entre 100 millones y 5 mil millones de parámetros, una fracción de lo que utilizan los LLM. A pesar de su tamaño más pequeño, están diseñados para realizar tareas lingüísticas complejas de manera eficiente, abordando la creciente necesidad de inteligencia en el dispositivo en tiempo real. La investigación sobre SLM es crucial, ya que representa el futuro de una IA accesible y eficiente que pueda operar sin depender de una extensa infraestructura en la nube.
Uno de los desafíos críticos de la PNL moderna es optimizar los modelos de IA para dispositivos con recursos computacionales limitados. Los LLM, si bien son poderosos, consumen muchos recursos y a menudo requieren cientos de miles de GPU para funcionar de manera efectiva. Esta demanda computacional restringe su implementación a centros de datos centralizados, lo que limita su capacidad para funcionar en dispositivos portátiles que requieren respuestas en tiempo real. El desarrollo de SLM aborda este problema mediante la creación de modelos eficientes que se ejecutan directamente en el dispositivo y al mismo tiempo mantienen un alto rendimiento en diversas tareas lingüísticas. Los investigadores han reconocido la importancia de equilibrar el desempeño con la eficiencia, con el objetivo de crear modelos que requieran menos recursos pero que aún realicen tareas como razonamiento de sentido común, aprendizaje en contexto y resolución de problemas matemáticos.
Los investigadores han explorado métodos para reducir la complejidad de modelos grandes sin comprometer su capacidad para desempeñarse bien en tareas clave. Se han utilizado comúnmente métodos como la poda de modelos, la destilación de conocimientos y la cuantificación. La poda elimina neuronas menos importantes de un modelo para reducir su tamaño y carga computacional. La destilación de conocimiento transfiere conocimiento de un modelo más grande a uno más pequeño, permitiendo que el modelo más pequeño replique el comportamiento de su contraparte más grande. La cuantificación reduce la precisión de los cálculos, lo que ayuda a acelerar el modelo y reducir el uso de memoria. Además, innovaciones como el uso compartido de parámetros y el escalado por capas han optimizado aún más los modelos para que funcionen bien en dispositivos como teléfonos inteligentes y tabletas. Si bien estos métodos han ayudado a mejorar la eficiencia de los SLM, a menudo no son suficientes para lograr el mismo nivel de desempeño que los LLM sin un mayor perfeccionamiento.
La investigación de la Universidad de Correos y Telecomunicaciones de Beijing (BUPT), el Laboratorio Peng Cheng, Helixon Research y la Universidad de Cambridge presenta nuevos diseños arquitectónicos destinados a promover los SLM. Su trabajo se centra en modelos basados únicamente en decodificadores y basados en transformadores, lo que permite un procesamiento más eficiente en el dispositivo. Para minimizar las demandas computacionales, introdujeron innovaciones como mecanismos de atención de consultas múltiples y redes neuronales de retroalimentación (FFN) cerradas. Por ejemplo, la atención de consultas múltiples reduce la sobrecarga de memoria típicamente asociada con el mecanismo de atención en los modelos de transformadores. Al mismo tiempo, la estructura FFN cerrada permite que el modelo enrute información a través de la red, mejorando la eficiencia de forma dinámica. Estos avances permiten que modelos más pequeños realicen tareas de manera efectiva, desde la comprensión del lenguaje hasta el razonamiento y la resolución de problemas, mientras consumen menos recursos computacionales.
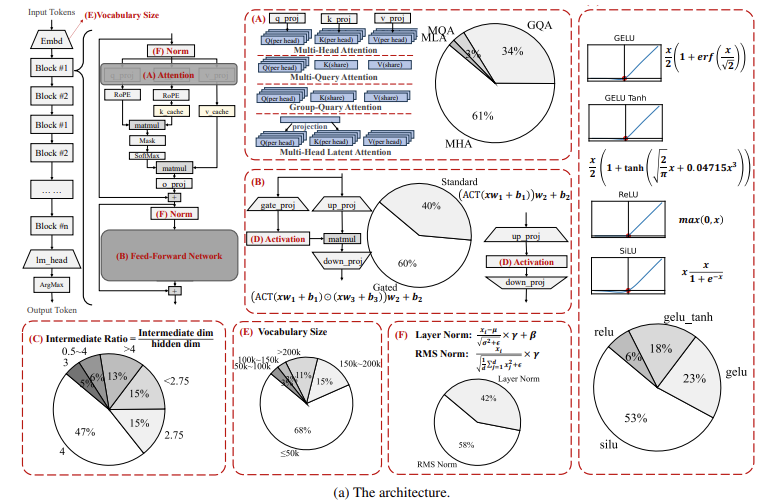
La arquitectura propuesta por los investigadores gira en torno a optimizar el uso de la memoria y la velocidad de procesamiento. La introducción de la atención de consultas grupales permite que el modelo reduzca la cantidad de grupos de consultas preservando al mismo tiempo la diversidad de atención. Este mecanismo ha demostrado ser particularmente eficaz para reducir el uso de memoria. Utilizan SiLU (Unidad lineal sigmoidea) como función de activación, lo que muestra marcadas mejoras en el manejo de tareas lingüísticas en comparación con funciones más convencionales como ReLU. Además, los investigadores introdujeron la compensación de no linealidad para abordar problemas comunes con modelos pequeños, como el problema del colapso de características, que afecta la capacidad de un modelo para procesar datos complejos. Esta compensación se logra mediante la integración de atajos matemáticos avanzados en la arquitectura del transformador, lo que garantiza que el modelo siga siendo robusto incluso cuando se reduce. Además, se implementaron técnicas de intercambio de parámetros, que permiten que el modelo reutilice pesos en diferentes capas, reduciendo aún más el consumo de memoria y mejorando los tiempos de inferencia, haciéndolo adecuado para dispositivos con capacidad computacional limitada.
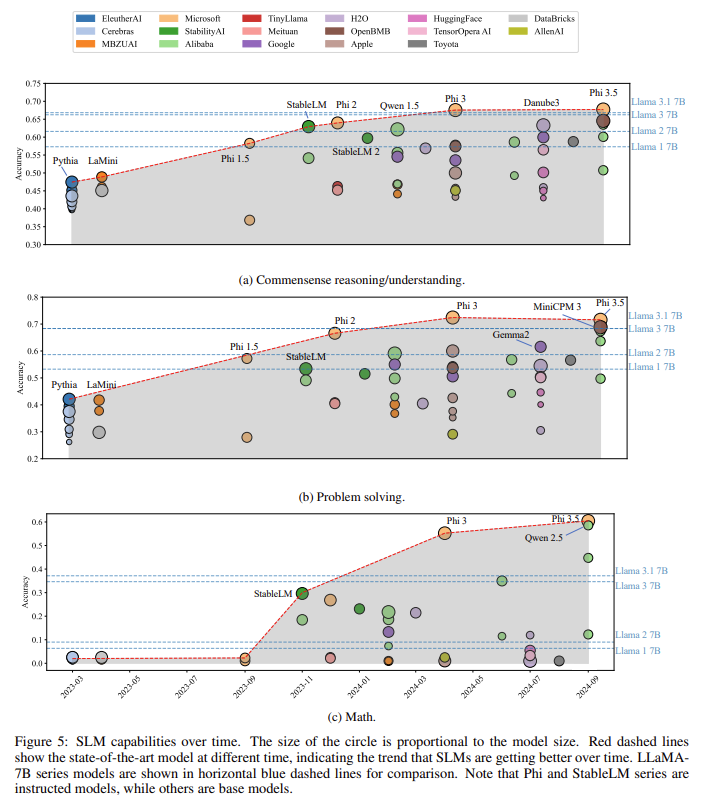
Los resultados de este estudio demuestran mejoras sustanciales tanto en el rendimiento como en la eficiencia. Uno de los modelos destacados, Phi-3 mini, logró una precisión un 14,5% mayor en tareas de razonamiento matemático que el LLaMA 3.1 de última generación, un modelo de lenguaje grande con 7 mil millones de parámetros. Además, en tareas de razonamiento de sentido común, la familia de modelos Phi superó a varios modelos líderes, incluido LLaMA, al lograr una puntuación de precisión del 67,6%. De manera similar, el modelo Phi-3 registró una precisión del 72,4 % en tareas de resolución de problemas, lo que lo sitúa entre los SLM de mejor rendimiento. Estos resultados resaltan el éxito de la nueva arquitectura a la hora de mantener un alto rendimiento y al mismo tiempo reducir las demandas computacionales típicamente asociadas con modelos más grandes. La investigación también demostró que estos modelos son eficientes y escalables, y ofrecen un rendimiento consistente en diversas tareas, desde razonamientos simples hasta problemas matemáticos más complejos.
En cuanto a la implementación, los modelos se probaron en varios dispositivos de vanguardia, incluido el Jetson Orin NX y teléfonos inteligentes de alta gama. Los modelos demostraron reducciones significativas tanto en la latencia de inferencia como en el uso de memoria. Por ejemplo, el modelo Qwen-2 1.5B redujo la latencia de inferencia en más del 50%, lo que lo convierte en uno de los modelos más eficientes probados. El uso de la memoria se optimizó notablemente en modelos como el OpenELM-3B, que utilizaba hasta un 30% menos de memoria que otros modelos con un número de parámetros similar. Estos resultados son prometedores para el futuro de los SLM, ya que demuestran que es posible lograr un alto rendimiento en dispositivos con recursos limitados, abriendo la puerta a aplicaciones de IA en tiempo real en tecnologías móviles y portátiles.
Las conclusiones clave de la investigación se pueden resumir de la siguiente manera:
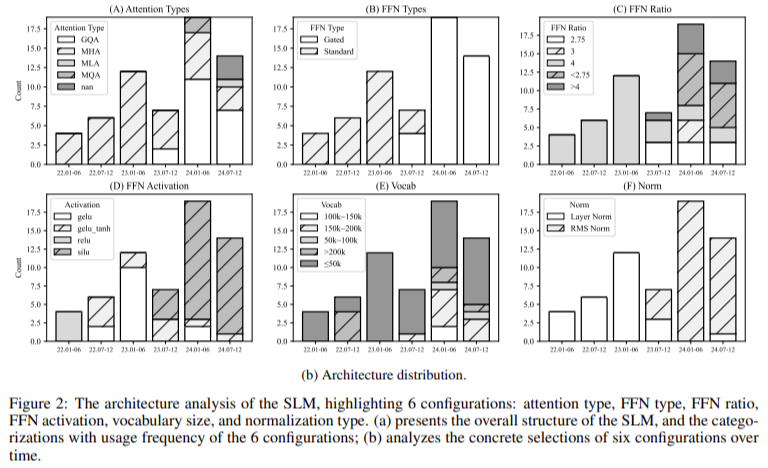
- Atención de consultas grupales y redes cerradas de retroalimentación (FFN): Estas innovaciones reducen significativamente el uso de memoria y el tiempo de procesamiento sin sacrificar el rendimiento. La atención de consultas grupales reduce la cantidad de consultas sin perder la diversidad de atención, lo que hace que el modelo sea más eficiente.
- Conjuntos de datos previos al entrenamiento de alta calidad: La investigación subraya la importancia de los conjuntos de datos de código abierto y de alta calidad, como FineWeb-Edu y DCLM. La calidad de los datos a menudo supera la cantidad, lo que permite una mejor capacidad de generalización y razonamiento.
- Uso compartido de parámetros y compensación de no linealidad: Estas técnicas juegan un papel crucial en la mejora del rendimiento en tiempo de ejecución de los modelos. El uso compartido de parámetros reduce la redundancia en las capas del modelo, mientras que la compensación de no linealidad aborda el problema del colapso de las características, lo que garantiza que el modelo siga siendo sólido en aplicaciones en tiempo real.
- Escalabilidad del modelo: A pesar de su tamaño más pequeño, la familia de modelos Phi superó consistentemente a modelos más grandes como LLaMA en tareas que requieren razonamiento matemático y comprensión de sentido común, lo que demuestra que los SLM pueden rivalizar con los LLM cuando se diseñan correctamente.
- Implementación de borde eficiente: La reducción significativa de la latencia y el uso de memoria demuestra que estos modelos son adecuados para su implementación en dispositivos con recursos limitados, como teléfonos inteligentes y tabletas. Modelos como el Qwen-2 1.5B lograron una reducción de latencia de más del 50%, lo que confirma sus aplicaciones prácticas en escenarios en tiempo real.
- Innovaciones arquitectónicas con impacto en el mundo real: La introducción de técnicas como la atención de consultas grupales, FFN cerradas y el intercambio de parámetros demuestra que las innovaciones a nivel arquitectónico pueden generar mejoras sustanciales en el rendimiento sin aumentar los costos computacionales, lo que hace que estos modelos sean prácticos para una adopción generalizada en la tecnología cotidiana.
En conclusión, la investigación sobre modelos de lenguajes pequeños ofrece un camino a seguir para crear una IA altamente eficiente que pueda operar en varios dispositivos sin depender de una infraestructura basada en la nube. El problema de equilibrar el rendimiento con la eficiencia computacional se ha abordado mediante diseños arquitectónicos innovadores, como la atención de consultas grupales y los FFN cerrados, que permiten a los SLM ofrecer resultados comparables a los de los LLM a pesar de tener una fracción de los parámetros. La investigación muestra que con el conjunto de datos, la arquitectura y las estrategias de implementación adecuados, los SLM se pueden escalar para manejar diversas tareas, desde el razonamiento hasta la resolución de problemas, mientras se ejecutan de manera eficiente en dispositivos con recursos limitados. Esto representa un avance significativo para hacer que la IA sea más accesible y funcional para aplicaciones del mundo real, garantizando que los beneficios de la inteligencia artificial puedan llegar a los usuarios en diferentes plataformas.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como empresario e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.