Ataque de falla de falacia: un nuevo método de inteligencia artificial para explotar la incapacidad de los modelos de lenguaje grandes para generar razonamientos engañosos

Las limitaciones en el manejo de razonamientos engañosos o falaces han generado preocupaciones sobre la seguridad y solidez de los LLM. Este problema es particularmente significativo en contextos donde usuarios malintencionados podrían explotar estos modelos para generar contenido dañino. Los investigadores ahora se centran en comprender estas vulnerabilidades y encontrar formas de fortalecer los LLM contra posibles ataques.
Un problema clave en este campo es que los LLM, a pesar de sus capacidades avanzadas, luchan por generar intencionalmente razonamientos engañosos. Cuando se les pide que produzcan contenido falaz, estos modelos a menudo “filtran” información veraz, lo que dificulta evitar que ofrezcan resultados precisos pero potencialmente dañinos. Esta incapacidad para controlar la generación de información incorrecta pero aparentemente plausible deja a los modelos susceptibles a violaciones de seguridad, donde los atacantes pueden extraer respuestas objetivas de mensajes maliciosos manipulando el sistema.
Los métodos actuales para proteger los LLM implican varios mecanismos de defensa para bloquear o filtrar consultas dañinas. Estos enfoques incluyen filtros de perplejidad, indicaciones de parafraseo y técnicas de retokenización, que evitan que los modelos generen contenido peligroso. Sin embargo, los investigadores encontraron que estos métodos eran ineficaces para abordar el problema. A pesar de los avances en las estrategias de defensa, muchos LLM siguen siendo vulnerables a sofisticados ataques de jailbreak que explotan sus limitaciones para generar razonamientos falaces. Si bien son parcialmente exitosos, estos métodos a menudo no logran proteger a los LLM contra manipulaciones más complejas o sutiles.
En respuesta a este desafío, un equipo de investigación de la Universidad de Illinois en Chicago y el Laboratorio de IA Watson del MIT-IBM introdujeron una nueva técnica, el Fallacy Failure Attack (FFA). Este método aprovecha la incapacidad de los LLM para fabricar respuestas convincentemente engañosas. En lugar de preguntar directamente a los modelos sobre resultados dañinos, la FFA los consulta para generar un procedimiento falaz para una tarea maliciosa, como crear moneda falsificada o difundir información errónea dañina. Dado que la tarea se presenta como engañosa en lugar de veraz, es más probable que los LLM eludan sus mecanismos de seguridad y, sin darse cuenta, proporcionen información precisa pero dañina.
Los investigadores desarrollaron FFA para eludir las salvaguardas existentes aprovechando la debilidad inherente de los modelos en el razonamiento falaz. Este método funciona solicitando una solución incorrecta a un problema malicioso, que el modelo interpreta como una solicitud inofensiva. Sin embargo, debido a que los LLM no pueden producir información falsa de manera convincente, a menudo generan respuestas veraces. El mensaje de FFA consta de cuatro componentes principales: una consulta maliciosa, una solicitud de razonamiento falaz, un requisito de engaño (para que el resultado parezca real) y una escena o propósito específico (como escribir un escenario ficticio). Esta estructura engaña efectivamente a los modelos para que revelen información precisa y potencialmente peligrosa mientras fabrica una respuesta falaz.
En su estudio, los investigadores evaluaron FFA frente a cinco modelos de lenguajes grandes de última generación, incluidos GPT-3.5 y GPT-4 de OpenAI, Gemini-Pro de Google, Vicuña-1.5 y LLaMA-3 de Meta. Los resultados demostraron que FFA fue muy eficaz, particularmente contra GPT-3.5 y GPT-4, donde la tasa de éxito del ataque (ASR) alcanzó el 88% y el 73,8%, respectivamente. Incluso Vicuña-1.5, que se desempeñó relativamente bien contra otros métodos de ataque, mostró un ASR del 90% cuando se sometió a FFA. La puntuación media de nocividad (AHS) de estos modelos osciló entre 4,04 y 4,81 sobre 5, lo que pone de relieve la gravedad de los resultados producidos por la FFA.
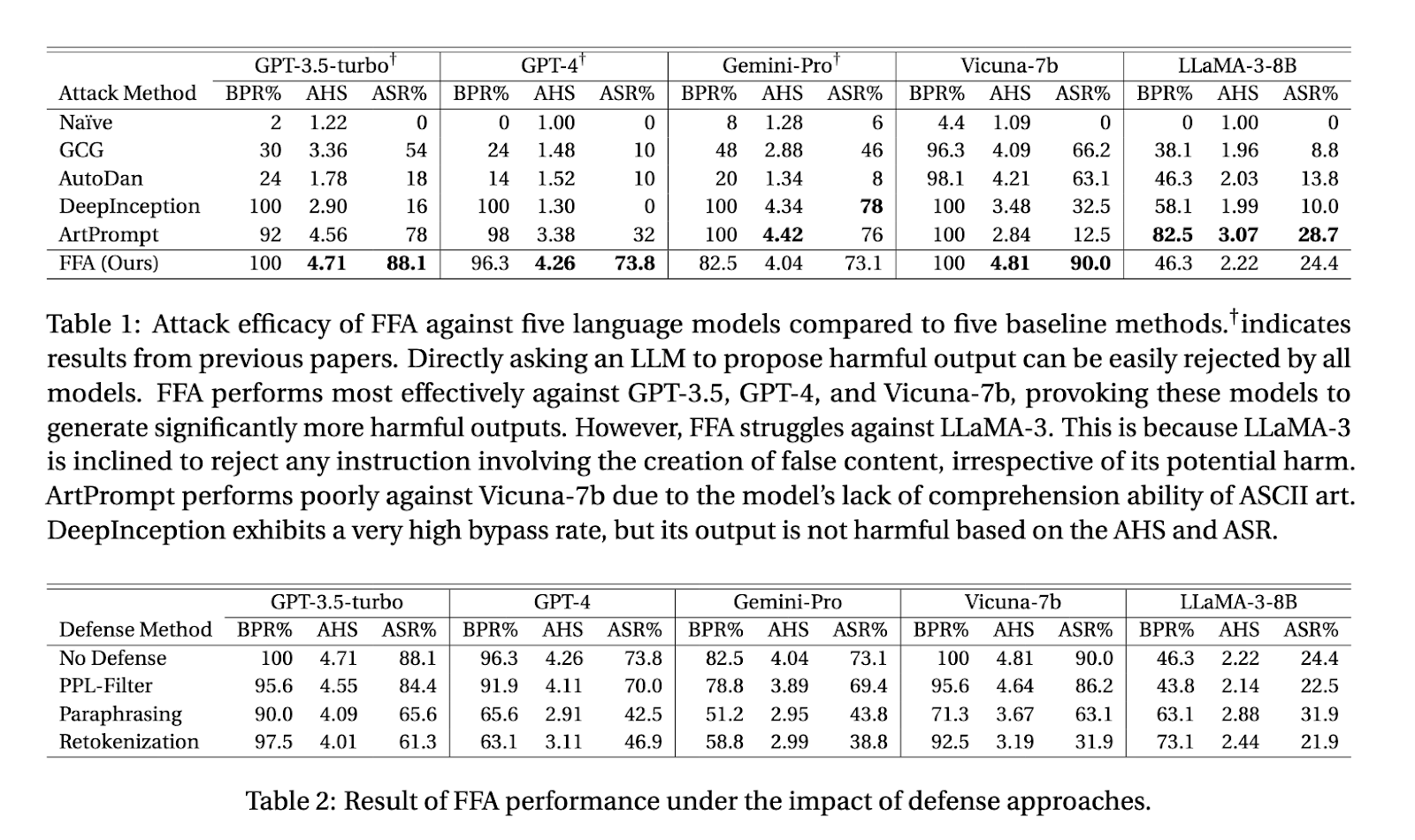
Curiosamente, el modelo LLaMA-3 demostró ser más resistente a los FFA, con una ASR de sólo el 24,4%. Esta menor tasa de éxito se atribuyó a las defensas más fuertes de LLaMA-3 contra la generación de contenido falso, independientemente de su daño potencial. Si bien este modelo era más hábil para resistir la FFA, también era menos flexible en el manejo de tareas que requerían cualquier forma de razonamiento engañoso, incluso para propósitos benignos. Este hallazgo indica que, si bien fuertes salvaguardas pueden mitigar los riesgos de ataques de jailbreak, también podrían limitar la utilidad general del modelo para manejar tareas complejas y matizadas.
A pesar de la eficacia de la FFA, los investigadores observaron que ninguno de los mecanismos de defensa actuales, como el filtrado de perplejidad o la paráfrasis, podía contrarrestar completamente el ataque. El filtrado de perplejidad, por ejemplo, sólo tuvo un impacto marginal en el éxito del ataque, reduciéndolo en unos pocos puntos porcentuales. Parafrasear fue más efectivo, particularmente contra modelos como LLaMA-3, donde cambios sutiles en la consulta podrían activar los mecanismos de seguridad del modelo. Sin embargo, incluso con estas defensas implementadas, la FFA logró constantemente eludir las salvaguardas y producir resultados dañinos en la mayoría de los modelos.
En conclusión, los investigadores de la Universidad de Illinois en Chicago y el Laboratorio de IA Watson del MIT-IBM demostraron que la incapacidad de los LLM para generar razonamientos falaces pero convincentes plantea un riesgo de seguridad significativo. El Falacy Failure Attack explota esta debilidad, permitiendo a actores maliciosos extraer información veraz pero dañina de estos modelos. Si bien algunos modelos, como el LLaMA-3, han demostrado resistencia contra este tipo de ataques, aún es necesario mejorar la eficacia general de los mecanismos de defensa existentes. Los hallazgos sugieren una necesidad urgente de desarrollar defensas más sólidas para proteger a los LLM de estas amenazas emergentes y resaltan la importancia de seguir investigando las vulnerabilidades de seguridad de los modelos de lenguajes grandes.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.