Investigadores de Microsoft presentan un sistema avanzado de categorización de consultas para mejorar la precisión de los modelos de lenguaje grande y reducir las alucinaciones en campos especializados

Los modelos de lenguaje grande (LLM) han revolucionado el campo de la IA con su capacidad para generar texto similar al humano y realizar razonamientos complejos. Sin embargo, a pesar de sus capacidades, los LLM necesitan ayuda con tareas que requieren conocimientos de dominios específicos, especialmente en atención médica, derecho y finanzas. Cuando se entrenan con grandes conjuntos de datos, estos modelos a menudo pierden información crítica de dominios especializados, lo que genera alucinaciones o respuestas inexactas. Se ha propuesto mejorar los LLM con datos externos como una solución a estas limitaciones. Al integrar información relevante, los modelos se vuelven más precisos y efectivos, mejorando significativamente su desempeño. La técnica de recuperación-generación aumentada (RAG) es un excelente ejemplo de este enfoque, que permite a los LLM recuperar los datos necesarios durante el proceso de generación para proporcionar respuestas más precisas y oportunas.
Uno de los problemas más importantes en la implementación de LLM es su incapacidad para manejar consultas que requieren información específica y actualizada. Si bien los LLM son muy capaces cuando se trata de conocimientos generales, fallan cuando se les asignan consultas especializadas o urgentes. Este déficit se produce porque la mayoría de los modelos se entrenan con datos estáticos, por lo que solo pueden actualizar sus conocimientos con aportaciones externas. Por ejemplo, en el ámbito de la atención sanitaria, un modelo que necesita acceso a las directrices médicas actuales tendrá dificultades para ofrecer consejos precisos, lo que podría poner vidas en riesgo. De manera similar, los sistemas legales y financieros requieren actualizaciones constantes para mantenerse al día con las regulaciones y condiciones del mercado cambiantes. Por lo tanto, el desafío radica en desarrollar un modelo que pueda extraer dinámicamente datos relevantes para satisfacer las necesidades específicas de estos dominios.
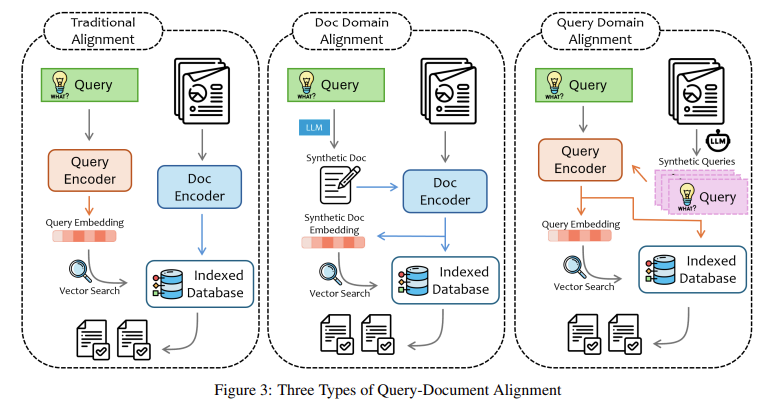
Las soluciones actuales, como el ajuste fino y RAG, han logrado avances para abordar estos desafíos. El ajuste fino permite volver a entrenar un modelo con datos de dominio específicos, adaptándolo para tareas particulares. Sin embargo, este enfoque lleva mucho tiempo y requiere una gran cantidad de datos de capacitación, que solo a veces están disponibles. Además, el ajuste fino a menudo resulta en un sobreajuste, donde el modelo se vuelve demasiado especializado y necesita ayuda con consultas generales. Por otro lado, RAG ofrece un enfoque más flexible. En lugar de depender únicamente de conocimientos previamente entrenados, RAG permite que los modelos recuperen datos externos en tiempo real, mejorando su precisión y relevancia. A pesar de sus ventajas, RAG todavía enfrenta varios desafíos, como la dificultad de procesar datos no estructurados, que pueden presentarse en diversas formas, como texto, imágenes y tablas.
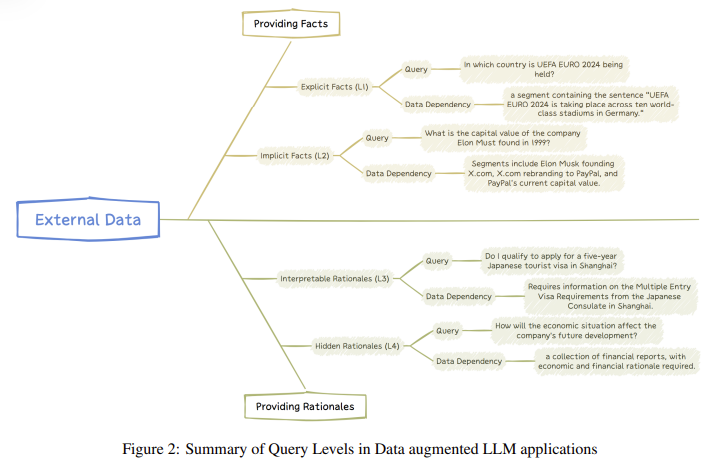
Los investigadores de Microsoft Research Asia introdujeron un método novedoso que clasifica las consultas de los usuarios en cuatro niveles distintos según la complejidad y el tipo de datos externos requeridos. Estos niveles son hechos explícitos, hechos implícitos, fundamentos interpretables y fundamentos ocultos. La categorización ayuda a adaptar el enfoque del modelo para recuperar y procesar datos, asegurando que seleccione la información más relevante para una tarea determinada. Por ejemplo, las consultas de hechos explícitos implican preguntas sencillas, como “¿Cuál es la capital de Francia?” donde la respuesta se puede recuperar a partir de datos externos. Las consultas de hechos implícitos requieren más razonamiento, como combinar múltiples datos para inferir una conclusión. Las consultas de fundamentos interpretables implican pautas específicas de dominio, mientras que las consultas de fundamentos ocultos requieren un razonamiento profundo y, a menudo, tratan con conceptos abstractos.
El método propuesto por Microsoft Research permite a los LLM diferenciar entre estos tipos de consultas y aplicar el nivel apropiado de razonamiento. Por ejemplo, en el caso de consultas de fundamentos ocultos, donde no existe una respuesta clara, el modelo podría inferir patrones y utilizar métodos de razonamiento de dominios específicos para generar una respuesta. Al dividir las consultas en estas categorías, el modelo se vuelve más eficiente a la hora de recuperar la información necesaria y proporcionar respuestas precisas basadas en el contexto. Esta categorización también ayuda a reducir la carga computacional en el modelo, ya que ahora puede centrarse en recuperar solo los datos relevantes para el tipo de consulta en lugar de escanear grandes cantidades de información no relacionada.
El estudio también destaca los impresionantes resultados de este enfoque. El sistema mejoró significativamente el rendimiento en dominios especializados como la atención sanitaria y el análisis jurídico. Por ejemplo, en aplicaciones sanitarias, el modelo redujo la tasa de alucinaciones hasta en un 40%, proporcionando respuestas más fundamentadas y fiables. La precisión del modelo a la hora de procesar documentos complejos y ofrecer análisis detallados aumentó un 35% en los sistemas legales. En general, el método propuesto permitió una recuperación más precisa de datos relevantes, lo que condujo a una mejor toma de decisiones y resultados más confiables. El estudio encontró que los sistemas basados en RAG redujeron los incidentes de alucinaciones al basar las respuestas del modelo en datos verificables, mejorando la precisión en aplicaciones críticas como el diagnóstico médico y el procesamiento de documentos legales.

En conclusión, esta investigación proporciona una solución crucial a uno de los problemas fundamentales en la implementación de LLM en dominios especializados. Al introducir un sistema que clasifica las consultas según la complejidad y el tipo, los investigadores de Microsoft Research han desarrollado un método que mejora la precisión y la interpretabilidad de los resultados del LLM. Este marco permite a los LLM recuperar los datos externos más relevantes y aplicarlos de manera efectiva a consultas de dominios específicos, reduciendo las alucinaciones y mejorando el rendimiento general. El estudio demostró que el uso de la categorización de consultas estructuradas puede mejorar los resultados hasta en un 40%, lo que lo convierte en un importante paso adelante en los sistemas impulsados por IA. Al abordar tanto el problema de la recuperación de datos como la integración de conocimientos externos, esta investigación allana el camino para aplicaciones LLM más confiables y sólidas en diversas industrias.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como empresario e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.