RxEnvironments.jl: un enfoque de programación reactiva para simulaciones complejas de agente-entorno en el lenguaje Julia

El Principio de Energía Libre (FEP) y su extensión, la Inferencia Activa (AIF), presentan un enfoque único para comprender la autoorganización en los sistemas naturales. Estos marcos proponen que los agentes utilicen modelos generativos internos para predecir observaciones de procesos externos desconocidos, actualizando continuamente sus estados de percepción y control para minimizar los errores de predicción. Si bien este principio unificador ofrece conocimientos profundos sobre las interacciones agente-entorno, implementarlo en escenarios prácticos plantea desafíos importantes. Los investigadores requieren un control detallado sobre los protocolos de comunicación agente-entorno, particularmente cuando simulan retroalimentación propioceptiva o sistemas multiagente. Las soluciones actuales de la teoría del control y el aprendizaje por refuerzo, como Gymnasium, necesitan más flexibilidad para estas simulaciones complejas. El estilo de programación imperativo empleado en los marcos existentes restringe la comunicación entre agentes y entornos a parámetros predefinidos, lo que limita la exploración de diversos escenarios de interacción esenciales para avanzar en la investigación de FEP y AIF.
Los intentos existentes de abordar los desafíos de la simulación de interacciones agente-entorno se han centrado principalmente en marcos de aprendizaje por refuerzo. Gymnasium se ha convertido en un estándar para crear y compartir entornos de control, ofreciendo una función escalonada para definir funciones de transición y manejar simulaciones ambientales. Alternativas similares incluyen Deepmind Control Suite para Python y ReinforcementLearning.jl para Julia. Estos paquetes proporcionan interfaces de alto nivel para los entornos, simplificando el cronometraje para los usuarios. Si bien están diseñados para el aprendizaje por refuerzo, se han adaptado para la investigación de Inferencia Activa. Otros paquetes como PyMDP y SPM-DEM incorporan la realización del entorno pero priorizan la creación de agentes. Sin embargo, la falta de un enfoque estandarizado para definir entornos de Inferencia Activa ha llevado a implementaciones inconsistentes, con algunos investigadores utilizando Gymnasium y otros optando por cajas de herramientas especializadas. La programación reactiva, similar al modelo de actor, ofrece una alternativa prometedora al permitir cálculos en conjuntos de datos estáticos y observaciones de sensores asíncronos en tiempo real, alineándose más estrechamente con los principios de la inferencia activa.
Investigadores de la Universidad Tecnológica de Eindhoven y GN Hearing presentes RxEnvironments.jlun paquete de Julia, que presenta entornos reactivos como un enfoque sólido para modelar las interacciones agente-entorno. Esta implementación utiliza principios de programación reactiva para crear simulaciones eficientes y flexibles. El paquete aborda las limitaciones de los marcos existentes al ofrecer una plataforma versátil para diseñar entornos complejos con múltiples agentes. Al adoptar un estilo de programación reactiva, RxEnvironments.jl permite a los investigadores modelar sistemas sofisticados con agentes que interactúan de manera más efectiva. El diseño del paquete facilita la exploración de varios escenarios, desde simples simulaciones de un solo agente hasta complejos ecosistemas de múltiples agentes. A través de varios estudios de casos, RxEnvironments.jl demuestra su capacidad para manejar configuraciones ambientales diversas y complejas, mostrando su potencial como una poderosa herramienta para avanzar en la investigación en Inferencia Activa y campos relacionados.
RxEnvironments.jl adopta un enfoque de programación reactiva para el diseño del entorno, abordando las limitaciones de los marcos imperativos. Este enfoque permite interacciones multimodales y multisensor entre agentes y entornos sin restricciones estrictas de comunicación. El paquete ofrece un control detallado sobre las observaciones, lo que permite que diferentes canales sensoriales funcionen con diferentes frecuencias o se activen en función de acciones específicas. Esta flexibilidad permite la implementación de escenarios complejos del mundo real con un control detallado sobre las percepciones de un agente. RxEnvironments.jl admite de forma nativa entornos de múltiples agentes, lo que permite que coexistan múltiples instancias del mismo tipo de agente sin codificación adicional. El estilo de programación reactiva garantiza un cálculo eficiente, con entornos que emiten observaciones cuando se les solicita y permanecen inactivos cuando no es necesario. Además de eso, el paquete va más allá de los simples marcos de entorno de agente y admite entornos complejos de múltiples entidades para simulaciones más sofisticadas.
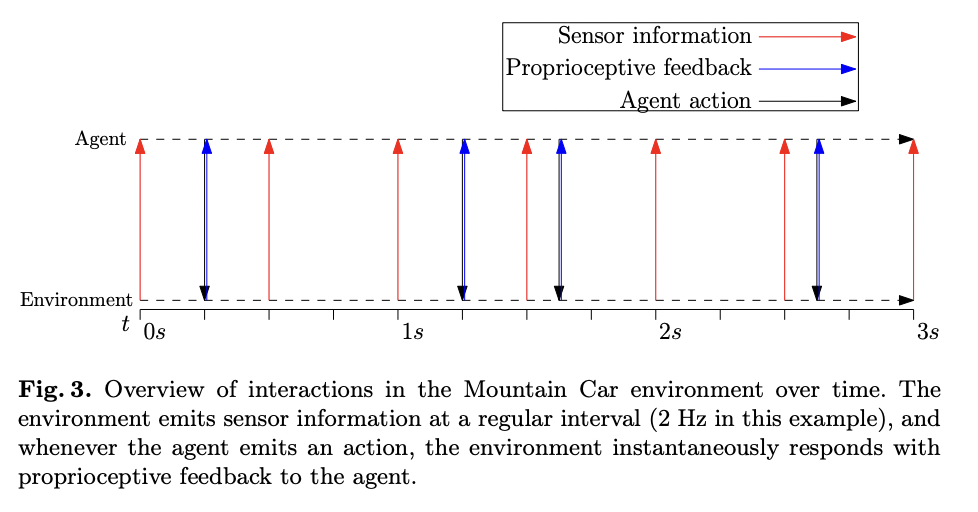
El entorno Mountain Car, un escenario clásico de aprendizaje por refuerzo, se implementa en RxEnvironments.jl con un toque único. Esta implementación muestra la capacidad del paquete para manejar interacciones complejas entre el agente y el entorno. Cuando un agente aplica una acción, como acelerar el motor, el entorno responde con una observación que contiene la fuerza real del motor aplicada. Este enfoque se alinea con las teorías actuales sobre la retroalimentación propioceptiva en los sistemas biológicos. El entorno está diseñado para activar diferentes implementaciones de la función what_to_send en función de los estímulos de entrada. Para las acciones del acelerador, devuelve la acción del acelerador aplicada, mientras que las mediciones de posición y velocidad se emiten a una frecuencia regular de 2 Hz, simulando el comportamiento del sensor. Esta configuración demuestra la capacidad de RxEnvironments.jl para gestionar distintos tipos de observaciones (retroalimentación sensorial y propioceptiva), cada una con su propia lógica de adquisición y transmisión.
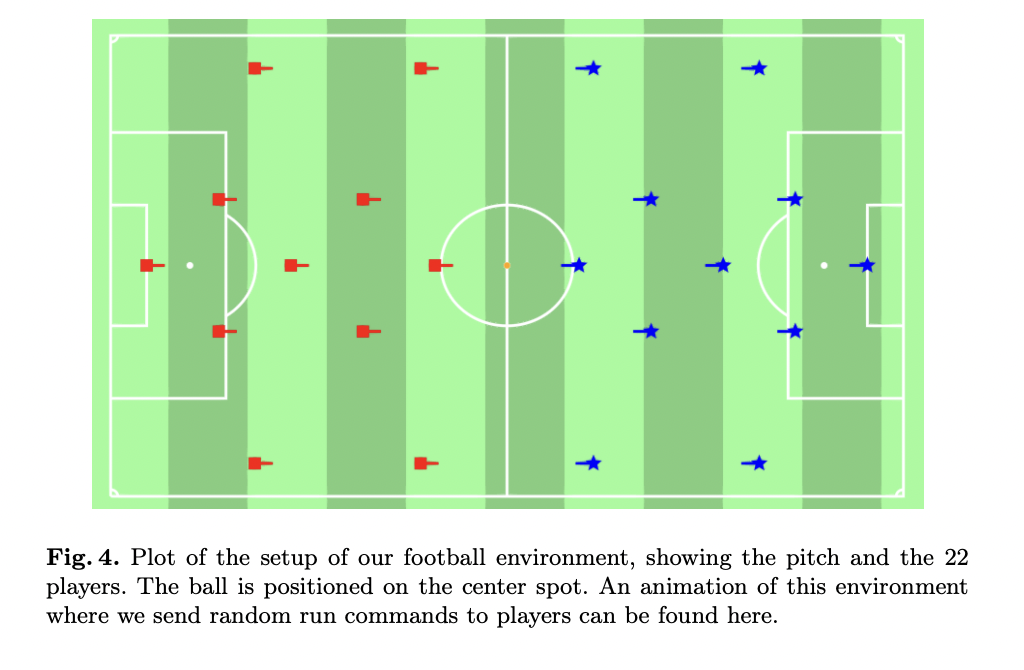
RxEnvironments.jl demuestra su versatilidad mediante la implementación de una compleja simulación de partido de fútbol. Este entorno de múltiples agentes involucra a 22 jugadores, lo que muestra la capacidad del paquete para manejar escenarios intrincados del mundo real. La simulación está estructurada con una única Entidad que representa el estado mundial, que contiene el balón y referencias a los 22 cuerpos de los jugadores, y 22 Entidades separadas para jugadores individuales. Este diseño permite una detección realista de colisiones y acciones sobre el balón. Los jugadores se suscriben a la Entidad Mundial pero no entre sí, lo que agiliza el gráfico de suscripción. La comunicación entre agentes se facilita a través de la Entidad mundial, que envía señales entre los jugadores. El entorno distingue entre estados globales y locales, donde la Entidad mundial gestiona las interacciones físicas y las Entidades jugadoras mantienen sus estados locales y reciben observaciones del estado global. Esta configuración permite la ejecución de comandos asincrónica para jugadores individuales, como se demuestra en un vídeo complementario. Si bien la simulación se centra en carreras y acciones con el balón en lugar de reglas integrales del fútbol, ilustra eficazmente la capacidad de RxEnvironments.jl para modelar sistemas complejos de múltiples agentes con observaciones e interacciones individualizadas.
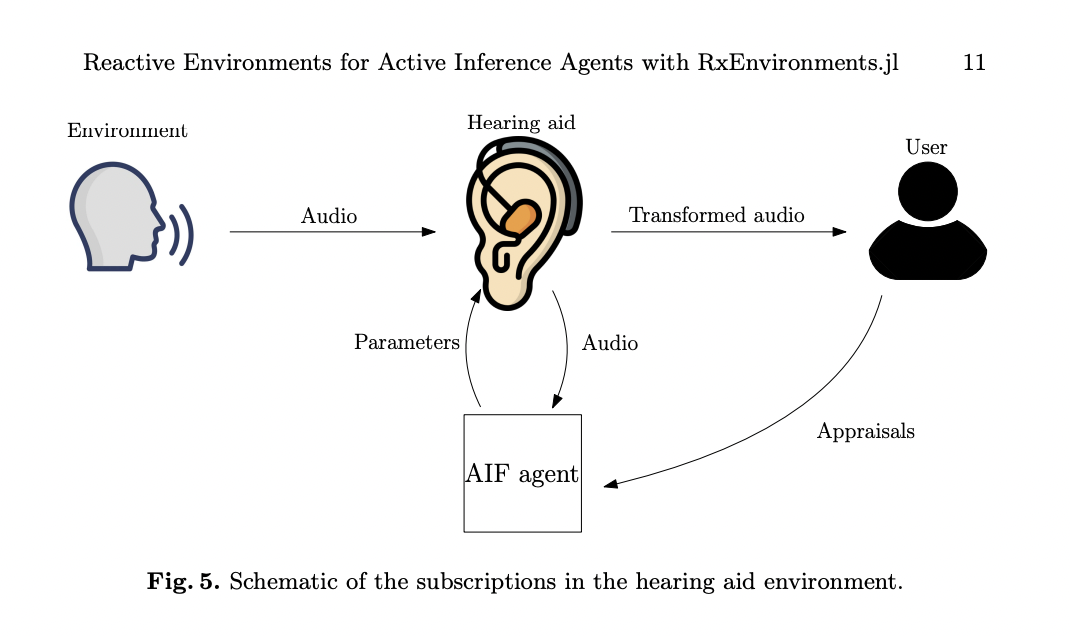
RxEnvironments.jl demuestra aún más su flexibilidad al modelar un sofisticado sistema de audífono que incorpora agentes activos basados en inferencia para la reducción del ruido. Este complejo escenario involucra múltiples entidades que interactúan: el propio audífono, el entorno acústico externo, el usuario (paciente) y un agente inteligente en el teléfono del usuario. El paquete maneja hábilmente los desafíos únicos de este sistema de múltiples entidades, donde el audífono debe comunicarse continuamente con tres fuentes distintas. Procesa señales acústicas del mundo exterior, recibe comentarios del usuario sobre el rendimiento percibido e interactúa con el agente inteligente del teléfono para realizar cálculos avanzados. Esta implementación muestra la capacidad de RxEnvironments.jl para modelar sistemas del mundo real con procesamiento distribuido y múltiples canales de comunicación, abordando las limitaciones de la potencia informática y la capacidad de la batería limitadas en los audífonos. El enfoque de programación reactiva del paquete permite una gestión eficiente de estas interacciones complejas y asincrónicas, lo que lo convierte en una herramienta ideal para simular y desarrollar tecnologías avanzadas de audífonos.
Este estudio presenta los entornos reactivos y su implementación en RxEnvironments.jl, que ofrece un marco versátil para modelar interacciones complejas entre agente y entorno. Este enfoque abarca escenarios tradicionales de aprendizaje por refuerzo al tiempo que permite simulaciones más sofisticadas, particularmente para la inferencia activa. Los estudios de caso demuestran el poder expresivo del marco, que se adapta a diversas configuraciones ambientales, desde problemas de control clásicos hasta sistemas multiagente y simulaciones avanzadas de audífonos. La flexibilidad de RxEnvironments.jl para manejar protocolos de comunicación complejos entre agentes y entornos lo posiciona como una herramienta valiosa para los investigadores. El trabajo futuro podría explorar clases de agentes que utilicen eficazmente este protocolo de comunicación, avanzando aún más en el campo de las simulaciones agente-entorno.
Mira el Papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.