SELMA: un nuevo enfoque de IA para mejorar los modelos de generación de texto a imagen utilizando datos generados automáticamente y técnicas de aprendizaje de habilidades específicas

Los modelos de texto a imagen (T2I) han experimentado un rápido progreso en los últimos años, permitiendo la generación de imágenes complejas basadas en entradas de lenguaje natural. Sin embargo, incluso los modelos T2I de última generación necesitan ayuda para capturar y reflejar con precisión toda la semántica en indicaciones determinadas, lo que genera imágenes en las que se pueden perder detalles cruciales, como múltiples sujetos o relaciones espaciales específicas. Por ejemplo, generar una composición como “un gato con alas volando sobre un campo de donas” plantea desafíos y obstáculos debido a la complejidad y especificidad inherentes del mensaje. A medida que estos modelos intentan comprender y replicar los matices de las descripciones textuales, sus limitaciones se vuelven evidentes. Además, la mejora de estos modelos a menudo se ve obstaculizada por la necesidad de conjuntos de datos anotados a gran escala y de alta calidad, lo que hace que requiera muchos recursos y sea laborioso. El resultado es un cuello de botella a la hora de lograr modelos que puedan generar imágenes consistentemente fieles y semánticamente precisas en diversos escenarios.
Un problema clave abordado por los investigadores es la necesidad de ayuda para crear imágenes que sean verdaderamente fieles a descripciones textuales complejas. Esta desalineación a menudo resulta en objetos faltantes, arreglos espaciales incorrectos o representación inconsistente de múltiples elementos. Por ejemplo, cuando se les pide que generen una imagen de una escena de parque con un banco, un pájaro y un árbol, es posible que los modelos T2I necesiten mantener las relaciones espaciales correctas entre estas entidades, lo que genera imágenes poco realistas. Las soluciones actuales intentan mejorar esta fidelidad mediante ajustes supervisados con datos anotados o mensajes de texto con subtítulos. Aunque estos métodos muestran mejoras, dependen en gran medida de la disponibilidad de una gran cantidad de datos anotados por humanos. Esta dependencia introduce altos costos y complejidad de capacitación. Por lo tanto, existe una necesidad apremiante de una solución que pueda mejorar la fidelidad de la imagen sin depender de la anotación manual de datos, lo cual es costoso y requiere mucho tiempo.
Muchas soluciones existentes han intentado abordar estos desafíos. Un enfoque popular son los métodos de ajuste fino supervisados, en los que los modelos T2I se entrenan utilizando pares de imagen y texto de alta calidad o conjuntos de datos seleccionados manualmente. Otra línea de investigación se centra en alinear los modelos T2I con los datos de preferencias humanas mediante el aprendizaje por refuerzo. Esto implica clasificar y calificar las imágenes en función de qué tan bien coinciden con las descripciones textuales y usar estas puntuaciones para ajustar aún más los modelos. Aunque estos métodos han demostrado ser prometedores para mejorar la alineación, dependen de extensas anotaciones manuales y datos de alta calidad. Además, se ha explorado la integración de componentes adicionales, como cuadros delimitadores o diseños de objetos, para guiar la generación de imágenes. Sin embargo, estas técnicas a menudo requieren un importante esfuerzo humano y curación de datos, lo que las hace poco prácticas a escala.
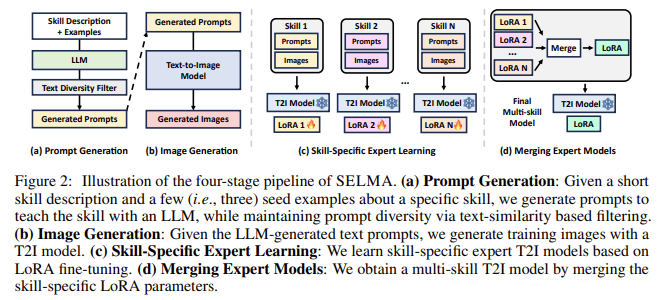
Investigadores de la Universidad de Carolina del Norte en Chapel Hill han presentado SELMA: Smatar-específico miexperto lganar y METROavanzando con ADatos autogenerados. SELMA presenta un enfoque novedoso para mejorar los modelos T2I sin depender de datos anotados por humanos. Este método aprovecha las capacidades de los modelos de lenguaje grande (LLM) para generar mensajes de texto específicos de habilidades automáticamente. Luego, los modelos T2I utilizan estas indicaciones para producir las imágenes correspondientes, creando un rico conjunto de datos sin intervención humana. Los investigadores emplean un método conocido como Adaptación de bajo rango (LoRA) para ajustar los modelos T2I en estos conjuntos de datos de habilidades específicas, lo que da como resultado múltiples modelos expertos de habilidades específicas. Al fusionar estos modelos expertos, SELMA crea un modelo T2I unificado de múltiples habilidades que puede generar imágenes de alta calidad con fidelidad y alineación semántica mejoradas.
SELMA opera a través de un proceso de cuatro etapas. En primer lugar, las indicaciones específicas de habilidades se generan mediante LLM, lo que ayuda a garantizar la diversidad en el conjunto de datos. La segunda etapa implica generar imágenes correspondientes basadas en estas indicaciones utilizando modelos T2I. A continuación, el modelo se ajusta utilizando módulos LoRA para especializarse en cada habilidad. Finalmente, estos expertos en habilidades específicas se fusionan para producir un modelo T2I robusto capaz de manejar diversas indicaciones. Este proceso de fusión reduce efectivamente los conflictos de conocimiento entre diferentes habilidades, lo que da como resultado un modelo que puede generar imágenes más precisas que los modelos tradicionales de múltiples habilidades. En promedio, SELMA mostró una mejora del +2,1 % en el punto de referencia de alineación de texto-imagen TIFA y una mejora del +6,9 % en el punto de referencia DSG, lo que indica su eficacia para mejorar la fidelidad.
El rendimiento de SELMA se validó frente a modelos T2I de última generación, como Stable Diffusion v1.4, v2 y XL. Los resultados empíricos demostraron que SELMA mejoró la fidelidad del texto y las métricas de preferencia humana en múltiples puntos de referencia, incluidos PickScore, ImageReward y Human Preference Score (HPS). Por ejemplo, el ajuste con SELMA mejoró el HPS en 3,7 puntos y las métricas de preferencia humana en 0,4 en PickScore y 0,39 en ImageReward. En particular, el ajuste con conjuntos de datos generados automáticamente se realizó de manera comparable al ajuste con datos reales. Los resultados sugieren que SELMA es una alternativa rentable sin anotaciones manuales extensas. Los investigadores descubrieron que ajustar un modelo T2I potente, como SDXL, utilizando imágenes generadas por un modelo más débil, como SD v2, conducía a mejoras de rendimiento, lo que sugiere el potencial de una generalización de débil a fuerte en los modelos T2I.
Conclusiones clave de la investigación SELMA:
- Mejora del rendimiento: SELMA mejoró los modelos T2I en un +2,1% en TIFA y un +6,9% en los puntos de referencia DSG.
- Generación de datos rentable: Los conjuntos de datos generados automáticamente lograron un rendimiento comparable al de los conjuntos de datos anotados por humanos.
- Métricas de preferencia humana: Se mejoró HPS en 3,7 puntos y se aumentaron PickScore e ImageReward en 0,4 y 0,39, respectivamente.
- Generalización de débil a fuerte: El ajuste fino con imágenes de un modelo más débil mejoró el rendimiento de un modelo T2I más fuerte.
- Dependencia reducida de la anotación humana: SELMA demostró que se podían desarrollar modelos T2I de alta calidad sin una extensa anotación manual de datos.

En conclusión, SELMA ofrece un enfoque sólido y eficiente para mejorar la fidelidad y la alineación semántica de los modelos T2I. Al aprovechar los datos generados automáticamente y un novedoso mecanismo de fusión para expertos en habilidades específicas, SELMA elimina la necesidad de costosos datos anotados por humanos. Este método aborda las limitaciones clave de los modelos T2I actuales y sienta las bases para futuros avances en la generación de texto a imagen.
Mira el Papel y Proyecto. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como empresario e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.