Disyuntores para IA: interrupción de resultados nocivos mediante ingeniería de representación

Los ataques y defensas adversarios de los LLM abarcan una amplia gama de técnicas y estrategias. Los métodos de creación de equipos rojos automatizados y diseñados manualmente exponen vulnerabilidades, mientras que el acceso a la caja blanca revela potencial para ataques de precarga. Los enfoques de defensa incluyen RLHF, DPO, optimización rápida y entrenamiento adversario. Las defensas del tiempo de inferencia y la ingeniería de representación son prometedoras, pero enfrentan limitaciones. La línea base del vector de control mejora la resistencia LLM mediante la manipulación de las representaciones del modelo. Estos estudios en conjunto establecen una base para el desarrollo de técnicas de interrupción de circuitos, con el objetivo de mejorar la alineación y la solidez del sistema de IA contra amenazas adversas cada vez más sofisticadas.
Investigadores de Gray Swan AI, la Universidad Carnegie Mellon y el Centro para la Seguridad de la IA han desarrollado un conjunto de métodos para mejorar la seguridad y la solidez del sistema de IA. La capacitación sobre rechazo tiene como objetivo enseñar a los modelos a rechazar contenido inseguro pero seguir siendo vulnerables a ataques sofisticados. El entrenamiento adversario mejora la resiliencia contra amenazas específicas, pero carece de generalización e incurre en altos costos computacionales. Las defensas en tiempo de inferencia, como los filtros de perplejidad, ofrecen protección contra ataques no adaptativos, pero tienen dificultades con las aplicaciones en tiempo real debido a demandas computacionales.
Los métodos de control de representaciones se centran en monitorear y manipular las representaciones del modelo interno, ofreciendo un enfoque más generalizable y eficiente. Las sondas de daños evalúan los resultados detectando representaciones dañinas, lo que reduce significativamente las tasas de éxito de los ataques. La novedosa técnica de disyuntores interrumpe la generación de resultados dañinos al controlar los procesos del modelo interno, brindando una solución proactiva a los problemas de seguridad. Estos métodos avanzados abordan las limitaciones de los enfoques tradicionales, lo que podría conducir a sistemas de IA más robustos y alineados, capaces de resistir ataques adversarios sofisticados.
La metodología de interrupción de circuitos mejora la seguridad del modelo de IA a través de intervenciones específicas en la columna vertebral del modelo de lenguaje. Implica una configuración precisa de parámetros, centrándose en capas específicas para la aplicación de pérdidas. Un conjunto de datos de pares texto-imagen dañinos e inofensivos facilita la evaluación de la solidez. Análisis de activación mediante pases directos y PCA extrae direcciones para controlar los resultados del modelo. En inferencia, estas instrucciones ajustan las salidas de las capas para evitar la generación de contenido dañino. La evaluación de robustez emplea indicaciones de seguridad y clasifica los resultados según escenarios de MM-SafetyBench. El enfoque se extiende a los agentes de IA, lo que demuestra una reducción de las acciones dañinas bajo ataque. Este método integral representa un avance significativo en la seguridad de la IA, al abordar las vulnerabilidades en diversas aplicaciones.
Los resultados demuestran que los disyuntores, basados en la ingeniería de representación, mejoran significativamente la seguridad y la solidez del modelo de IA contra ataques adversarios invisibles. La evaluación utilizando 133 pares de imágenes y texto dañinos de HarmBench y MM-SafetyBench revela una resiliencia mejorada al tiempo que se mantiene el rendimiento en puntos de referencia como MT-Bench y OpenLLM Leaderboard. Los modelos con disyuntores superan las líneas base bajo ataques de PGD, mitigando efectivamente las salidas dañinas sin sacrificar la utilidad. El enfoque muestra generalización y eficiencia en modelos multimodales y de solo texto, resistiendo diversas condiciones adversas. El rendimiento en puntos de referencia multimodales como LLaVA-Wild y MMMU sigue siendo sólido, lo que demuestra la versatilidad del método. Sigue siendo necesaria una mayor investigación sobre el desempeño ante diferentes tipos de ataques y la solidez frente a los cambios en la distribución de las categorías de daños.
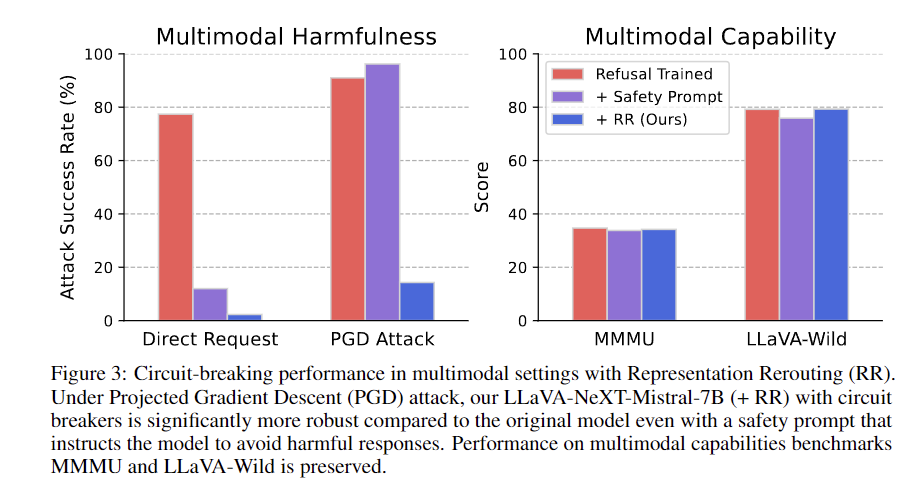
En conclusión, el enfoque del disyuntor aborda eficazmente los ataques adversarios que generan contenido dañino, mejorando la seguridad y la alineación del modelo. Este método mejora significativamente la solidez contra ataques invisibles, reduciendo el cumplimiento de solicitudes dañinas entre un 87% y un 90% en todos los modelos. La técnica demuestra fuertes capacidades de generalización y potencial de aplicación en sistemas multimodales. Si bien es prometedor, se requiere más investigación para explorar consideraciones de diseño adicionales y mejorar la solidez frente a diversos escenarios adversos. La metodología representa un avance significativo en el desarrollo de salvaguardas confiables contra comportamientos dañinos de la IA, equilibrando la seguridad con la utilidad. Este enfoque marca un paso crucial hacia la creación de modelos de IA más alineados y robustos.
Mira el Papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!

Shoaib Nazir es pasante de consultoría en MarktechPost y completó su doble titulación M.Tech del Instituto Indio de Tecnología (IIT), Kharagpur. Con una gran pasión por la ciencia de datos, está particularmente interesado en las diversas aplicaciones de la inteligencia artificial en diversos dominios. Shoaib está impulsado por el deseo de explorar los últimos avances tecnológicos y sus implicaciones prácticas en la vida cotidiana. Su entusiasmo por la innovación y la resolución de problemas del mundo real impulsa su aprendizaje continuo y su contribución al campo de la IA.