Este artículo sobre IA de China presenta un marco RLHF de aprendizaje por refuerzo con recompensas sólidas a partir de la retroalimentación humana para mejorar la estabilidad y el rendimiento de modelos de lenguaje grandes

El aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) se ha convertido en una técnica vital para alinear los modelos de lenguajes grandes (LLM) con los valores y expectativas humanos. Desempeña un papel fundamental para garantizar que los sistemas de IA se comporten de manera comprensible y confiable. RLHF mejora las capacidades de los LLM capacitándolos en función de comentarios que permiten a los modelos producir resultados más útiles, inofensivos y honestos. Este enfoque se utiliza ampliamente en el desarrollo de herramientas de inteligencia artificial que van desde agentes conversacionales hasta sistemas avanzados de apoyo a la toma de decisiones, con el objetivo de integrar las preferencias humanas directamente en el comportamiento del modelo.
A pesar de su importancia, RLHF enfrenta varios desafíos fundamentales. Uno de los principales problemas es la inestabilidad y las imperfecciones inherentes a los modelos de recompensa que guían el proceso de aprendizaje. Estos modelos de recompensa a menudo tergiversan las preferencias humanas debido a sesgos presentes en los datos de entrenamiento. Estos sesgos pueden conducir a cuestiones problemáticas como la piratería de recompensas, donde los modelos explotan las lagunas en la función de recompensa para obtener recompensas más altas sin mejorar realmente el desempeño de la tarea. Además, los modelos de recompensa a menudo sufren de sobreajuste y desajuste, lo que significa que no logran generalizar bien datos invisibles ni capturar patrones esenciales. En consecuencia, esta desalineación entre el comportamiento del modelo y la verdadera intención humana obstaculiza el rendimiento y la estabilidad de RLHF.
A pesar de los numerosos intentos de abordar estas cuestiones, sigue siendo urgente contar con un marco sólido para el RLHF. Los métodos convencionales, incluida la optimización de políticas próximas (PPO) y la estimación de máxima verosimilitud (MLE) para entrenar modelos de recompensa, se han mostrado prometedores, pero no han resuelto por completo las incertidumbres y los sesgos inherentes a los modelos de recompensa. Enfoques recientes, como las recompensas contrastivas o conjuntos de modelos de recompensa, han intentado mitigar estos problemas. Sin embargo, todavía luchan por mantener la estabilidad y la alineación en escenarios complejos del mundo real. La necesidad de un marco que pueda gestionar de manera sólida estos desafíos y garantizar resultados de aprendizaje confiables es más apremiante que nunca.
Investigadores de la Universidad de Tsinghua y Baichuan AI tienen un nuevo marco RLHF resistente a las recompensas. Este marco innovador utiliza conjuntos de modelos de recompensa bayesianos (BRME) para capturar y gestionar la incertidumbre en las señales de recompensa de manera efectiva. El uso de BRME permite que el marco incorpore múltiples perspectivas en la función de recompensa, reduciendo así el riesgo de desalineación e inestabilidad. El marco propuesto está diseñado para equilibrar el rendimiento y la solidez, haciéndolo más resistente a errores y sesgos. Al integrar BRME, el sistema puede seleccionar las señales de recompensa más confiables, lo que garantiza un aprendizaje más estable a pesar de los datos imperfectos o sesgados.
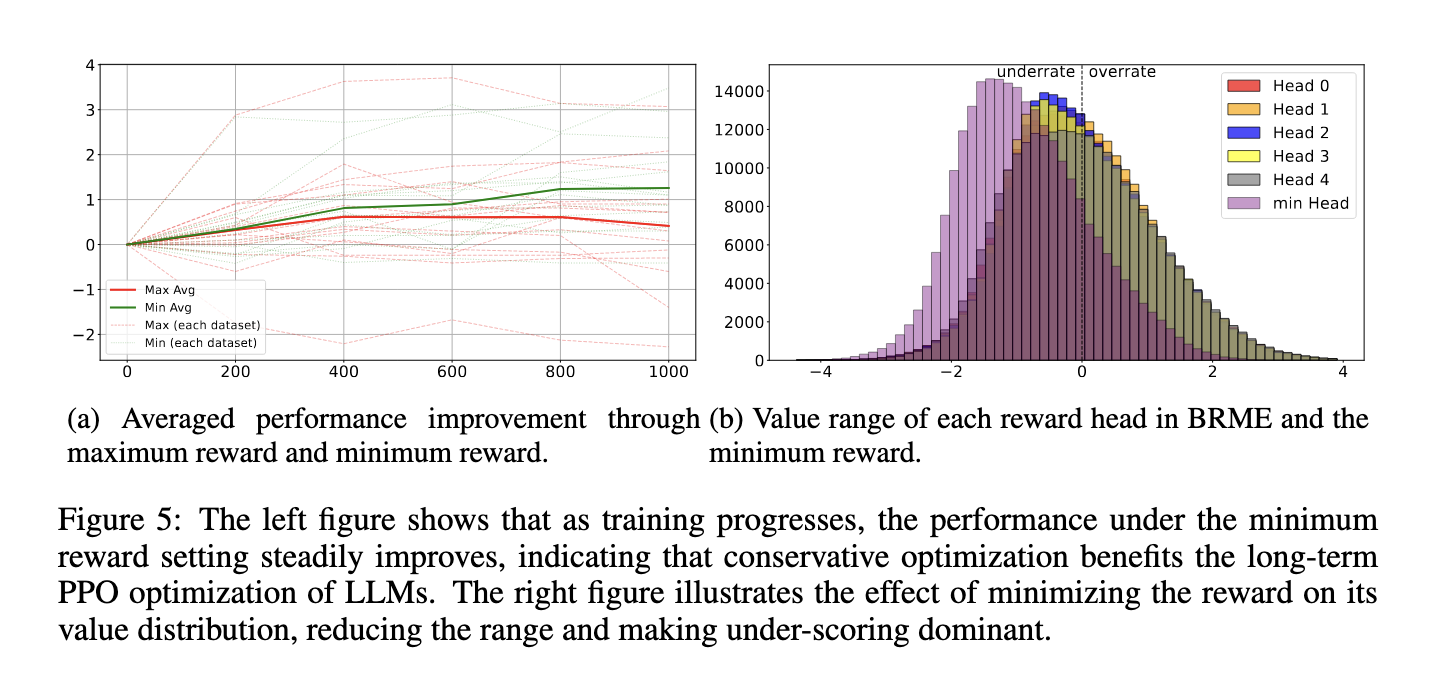
La metodología de este marco propuesto se centra en un modelo de recompensa de múltiples cabezas. Cada cabeza del modelo genera la media y la desviación estándar de una distribución gaussiana, que representa la recompensa. Este enfoque de múltiples cabezales captura los valores medios de recompensa y cuantifica la confianza en cada señal de recompensa. Durante el entrenamiento, la cabeza con la desviación estándar más baja se selecciona como función de recompensa nominal, filtrando efectivamente señales de recompensa no confiables. El marco aprovecha la pérdida del error cuadrático medio (MSE) para el entrenamiento, lo que garantiza que la desviación estándar de la salida refleje con precisión la confianza del modelo. A diferencia de los métodos tradicionales de RLHF, este enfoque evita que el modelo dependa demasiado de una única señal de recompensa, lo que mitiga el riesgo de piratería o desalineación de la recompensa.
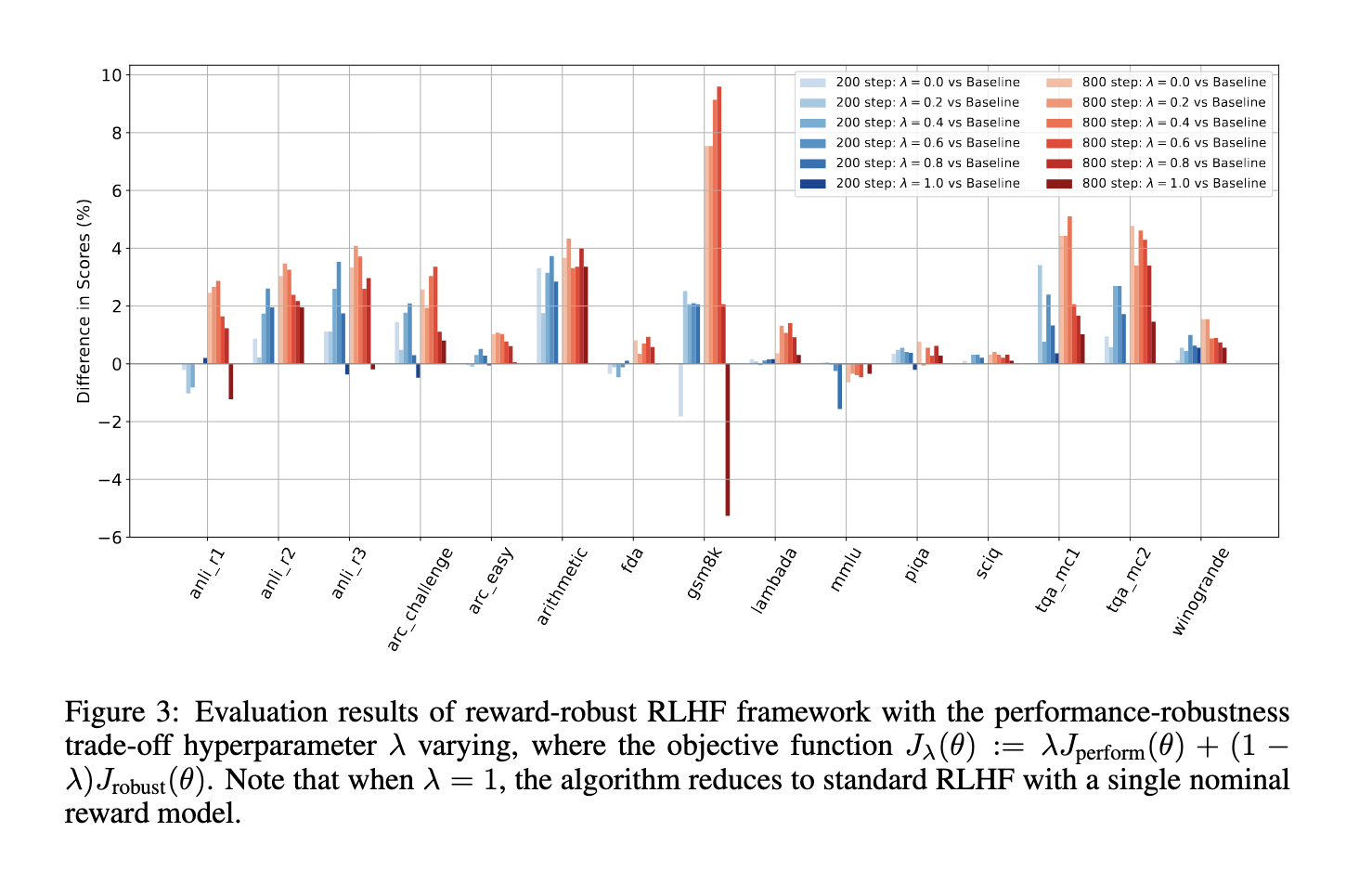
El marco RLHF de recompensa sólida propuesto ha demostrado un rendimiento impresionante, superando consistentemente a los métodos RLHF tradicionales en varios puntos de referencia. El equipo de investigación evaluó exhaustivamente su marco en 16 conjuntos de datos ampliamente utilizados, incluidos ARC, LAMBADA y MMLU, que cubren áreas como conocimiento general, razonamiento y computación numérica. Los resultados fueron convincentes y demostraron que el método propuesto logró un aumento promedio de precisión de aproximadamente el 4 % en comparación con el RLHF convencional. Además, cuando la incertidumbre de la recompensa se integró en el proceso de capacitación, el nuevo método mostró una ganancia de rendimiento del 2,42 % y del 2,03 % para tareas específicas, lo que subraya su capacidad para manejar señales de recompensa sesgadas e inciertas de manera efectiva. Por ejemplo, en el conjunto de datos LAMBADA, el método propuesto mejoró significativamente la estabilidad del rendimiento, reduciendo la fluctuación observada en los métodos tradicionales en un 3%. Esto no sólo mejora el rendimiento sino que también garantiza la estabilidad a largo plazo durante períodos de entrenamiento prolongados, una ventaja clave del marco.
La capacidad del marco RLHF de recompensa sólida para resistir la degradación del rendimiento, a menudo causada por señales de recompensa poco confiables, es un logro significativo. En escenarios donde los métodos tradicionales RLHF tienen dificultades, el método propuesto mantiene o incluso mejora el rendimiento del modelo, demostrando su potencial para aplicaciones del mundo real donde las señales de recompensa rara vez son perfectas. Esta estabilidad es crucial para implementar sistemas de IA que puedan adaptarse a entornos cambiantes y mantener un alto rendimiento en diversas condiciones, lo que subraya el valor práctico del marco.
En general, la investigación aborda desafíos fundamentales en el proceso RLHF mediante la introducción de un marco sólido que estabiliza el proceso de aprendizaje en grandes modelos lingüísticos. Al equilibrar el rendimiento nominal con la solidez, este novedoso método ofrece una solución confiable a problemas persistentes como la piratería de recompensas y la desalineación. El marco propuesto, desarrollado por la Universidad de Tsinghua y Baichuan AI, es prometedor para avanzar en el campo de la alineación de la IA y allanar el camino para sistemas de IA más seguros y eficaces.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Invitamos a startups, empresas e instituciones de investigación que trabajan en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.