Algoritmos conservadores para el aprendizaje por refuerzo de disparo cero con datos limitados

El aprendizaje por refuerzo (RL) es un dominio dentro de la inteligencia artificial que entrena a los agentes para tomar decisiones secuenciales mediante prueba y error en un entorno. Este enfoque permite al agente aprender interactuando con su entorno, recibiendo recompensas o penalizaciones en función de sus acciones. Sin embargo, capacitar a los agentes para que se desempeñen de manera óptima en tareas complejas requiere acceso a datos extensos y de alta calidad, lo que puede no siempre ser factible. Los datos limitados a menudo obstaculizan el aprendizaje, lo que lleva a una generalización deficiente y a una toma de decisiones subóptima. Por lo tanto, encontrar formas de mejorar la eficiencia del aprendizaje con conjuntos de datos pequeños o de baja calidad se ha convertido en un área esencial de investigación en RL.
Uno de los principales desafíos que enfrentan los investigadores de RL es el desarrollo de métodos que puedan funcionar de manera efectiva con conjuntos de datos limitados. Los enfoques convencionales de RL a menudo dependen de conjuntos de datos muy diversos recopilados mediante una exploración exhaustiva por parte de los agentes. Esta dependencia de grandes conjuntos de datos hace que los métodos tradicionales no sean adecuados para aplicaciones del mundo real, donde la recopilación de datos requiere mucho tiempo, es costosa y potencialmente peligrosa. En consecuencia, la mayoría de los algoritmos de RL funcionan mal cuando se entrenan en conjuntos de datos pequeños u homogéneos, ya que sobrestiman los valores de los pares estado-acción fuera de distribución (OOD), lo que lleva a una generación de políticas ineficaces.
Los métodos actuales de RL de tiro cero tienen como objetivo capacitar a los agentes para que realicen múltiples tareas sin exposición directa a las funciones durante el entrenamiento. Estos métodos aprovechan conceptos como medidas sucesoras y características sucesoras para generalizar entre tareas. Sin embargo, los métodos de RL de tiro cero existentes están limitados por su dependencia de conjuntos de datos grandes y heterogéneos para el entrenamiento previo. Esta dependencia plantea desafíos importantes cuando se aplica a escenarios del mundo real donde solo se encuentran disponibles conjuntos de datos pequeños u homogéneos. La degradación del rendimiento cuando se utilizan conjuntos de datos más pequeños se debe principalmente a la tendencia inherente de los métodos a sobreestimar los valores de estado-acción de OOD, un fenómeno bien observado en la RL fuera de línea de una sola tarea.
Un equipo de investigación de la Universidad de Cambridge y la Universidad de Bristol ha propuesto un nuevo marco conservador de RL de tiro cero. Este enfoque introduce modificaciones a los métodos de RL de tiro cero existentes al incorporar principios de RL conservadora, una estrategia muy adecuada para entornos de RL fuera de línea. Las modificaciones de los investigadores incluyen un regularizador sencillo para los valores de acción de estado de OOD, que se puede integrar en cualquier algoritmo RL de disparo cero. Este nuevo marco mitiga significativamente la sobreestimación de las acciones OOD y mejora el rendimiento cuando se capacita en conjuntos de datos pequeños o de baja calidad.
El marco conservador de RL de tiro cero emplea dos modificaciones principales: representaciones de valor conservador hacia adelante-hacia atrás (VC-FB) y representaciones de medida conservadora hacia adelante-hacia atrás (MC-FB). El método VC-FB suprime los valores de acción OOD en todos los vectores de tareas extraídos de una distribución específica, asegurando que la política del agente permanezca dentro de los límites de las acciones observadas. Por el contrario, el método MC-FB suprime los recuentos de visitas esperados para todos los vectores de tareas, lo que reduce la probabilidad de que el agente realice acciones OOD durante los escenarios de prueba. Estas modificaciones son fáciles de integrar en el proceso de entrenamiento de RL estándar y solo requieren un ligero aumento en la complejidad computacional.
El rendimiento de los algoritmos conservadores de RL de disparo cero se evaluó en tres conjuntos de datos: políticas de destilación de red aleatoria (RND), diversidad es todo lo que necesita (DIAYN) y aleatoria (RANDOM), cada una con diferentes niveles de calidad y tamaño de datos. Los métodos conservadores mostraron una mejora del rendimiento agregado de hasta 1,5 veces en comparación con las líneas de base no conservadoras. Por ejemplo, VC-FB logró una puntuación media intercuartil (IQM) de 148, mientras que la línea de base no conservadora obtuvo sólo 99 en el mismo conjunto de datos. Además, los resultados mostraron que los enfoques conservadores no comprometieron el rendimiento cuando se entrenaron en conjuntos de datos grandes y diversos, lo que validó aún más la solidez del marco propuesto.
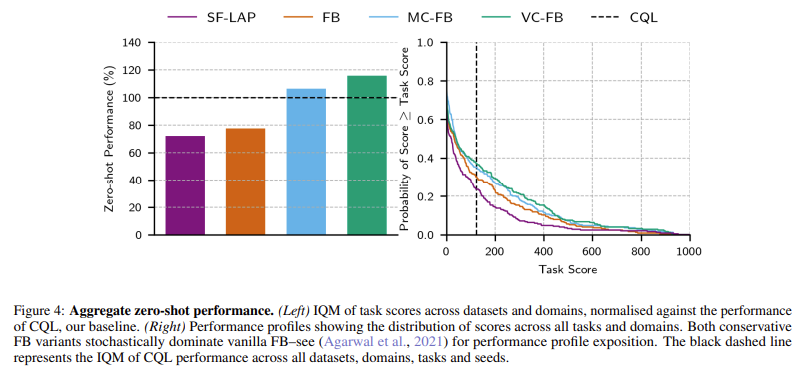
Conclusiones clave de la investigación:
- Los métodos conservadores de RL de tiro cero propuestos mejoran el rendimiento en conjuntos de datos de baja calidad hasta 1,5 veces en comparación con los métodos no conservadores.
- Se introdujeron dos modificaciones principales: VC-FB y MC-FB, que se centran en valorar y medir el conservadurismo.
- Los nuevos métodos mostraron una puntuación media intercuartil (IQM) de 148, superando la puntuación inicial de 99.
- Los algoritmos conservadores mantuvieron un alto rendimiento incluso en conjuntos de datos grandes y diversos, lo que garantiza adaptabilidad y solidez.
- El marco reduce significativamente la sobreestimación de los valores de acción del estado de OOD, abordando un desafío importante en el entrenamiento de RL con datos limitados.

En conclusión, el marco conservador de RL de tiro cero presenta una solución prometedora para capacitar a agentes de RL utilizando conjuntos de datos pequeños o de baja calidad. Las modificaciones propuestas ofrecen una mejora significativa del rendimiento, reduciendo el impacto de la sobreestimación del valor de OOD y mejorando la solidez de los agentes en diversos escenarios. Esta investigación es un paso hacia la implementación práctica de sistemas RL en aplicaciones del mundo real, lo que demuestra que se puede lograr una capacitación RL efectiva incluso sin conjuntos de datos grandes y diversos.
Mira el Papel y Proyecto. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
A Sana Hassan, pasante de consultoría en Marktechpost y estudiante de doble titulación en IIT Madras, le apasiona aplicar la tecnología y la inteligencia artificial para abordar los desafíos del mundo real. Con un gran interés en resolver problemas prácticos, aporta una nueva perspectiva a la intersección de la IA y las soluciones de la vida real.