Este artículo de IA presenta una novedosa estrategia de compresión de caché KV basada en normas L2 para modelos de lenguajes grandes

Los modelos de lenguajes grandes (LLM) están diseñados para comprender y gestionar tareas lingüísticas complejas mediante la captura del contexto y las dependencias a largo plazo. Un factor crítico para su desempeño es la capacidad de manejar entradas de contexto largo, lo que permite una comprensión más profunda del contenido en secuencias de texto extensas. Sin embargo, esta ventaja viene con el inconveniente de un mayor uso de memoria, ya que almacenar y recuperar información contextual de entradas anteriores puede consumir recursos computacionales sustanciales.
El consumo de memoria en los LLM se atribuye principalmente al almacenamiento de pares clave-valor (KV) durante la inferencia autorregresiva. En tal escenario, el modelo debe acceder repetidamente a estos pares almacenados para cada nuevo token que genera. A medida que aumenta la longitud de la secuencia, los requisitos de memoria crecen exponencialmente, lo que hace que su implementación no sea práctica en muchos entornos de hardware. Este problema se agrava aún más cuando los LLM se aplican a tareas de contexto prolongado, donde la secuencia completa debe conservarse en la memoria para realizar predicciones precisas. En consecuencia, reducir la huella de memoria de los LLM se ha convertido en una necesidad urgente para optimizar su rendimiento en aplicaciones del mundo real.
Los enfoques tradicionales para gestionar el uso de la memoria en los LLM implican algoritmos complejos o técnicas de ajuste adaptadas a arquitecturas de modelos individuales. Estos métodos a menudo incluyen la compresión post-hoc de la caché KV mediante el análisis de puntuaciones de atención o la introducción de cambios en el modelo mismo. Si bien son efectivas, estas estrategias están limitadas por su complejidad y la necesidad de recursos computacionales adicionales. Además, algunos de estos enfoques son incompatibles con los mecanismos de atención modernos como FlashAttention, que están diseñados para mejorar la eficiencia de la memoria. Por lo tanto, los investigadores han explorado nuevas técnicas efectivas y fácilmente adaptables para varios LLM.
Investigadores de la Universidad de Edimburgo y la Universidad Sapienza de Roma propusieron un enfoque novedoso para la compresión de caché KV que es más simple y eficiente que las soluciones existentes. Esta estrategia aprovecha la correlación entre la norma L2 de las incorporaciones clave y las puntuaciones de atención correspondientes, lo que permite que el modelo retenga solo los pares KV más impactantes. A diferencia de los métodos anteriores que requieren capacitación adicional o modificaciones complejas, este enfoque no es intrusivo y se puede implementar directamente en cualquier LLM solo decodificador basado en transformador. Al mantener solo los pares KV con la norma L2 más baja, los investigadores demostraron que el modelo podía reducir su huella de memoria manteniendo una alta precisión.
La metodología se basa en la observación de que las incrustaciones de claves con valores de norma L2 más bajos generalmente se asocian con puntuaciones de atención más altas durante la decodificación. Esto implica que dichas incorporaciones son más influyentes a la hora de determinar el resultado del modelo. Por lo tanto, retener solo estas incrustaciones de claves y sus valores correspondientes permite que el modelo comprima significativamente su caché KV sin perder información crítica. Esta estrategia es particularmente ventajosa ya que no depende del cálculo de puntuaciones de atención, lo que la hace compatible con varios mecanismos de atención, incluido FlashAttention. Además, se puede aplicar a cualquier modelo existente sin necesidad de un reentrenamiento extenso o cambios arquitectónicos, ampliando su aplicabilidad.
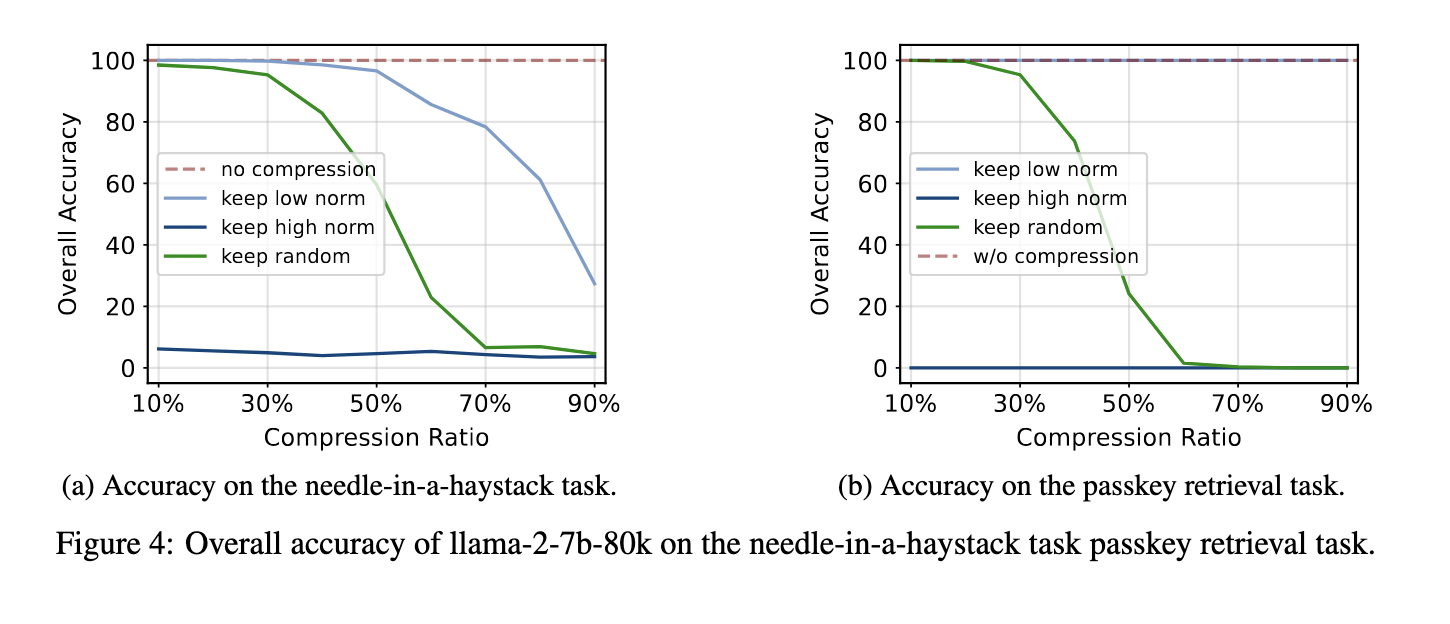
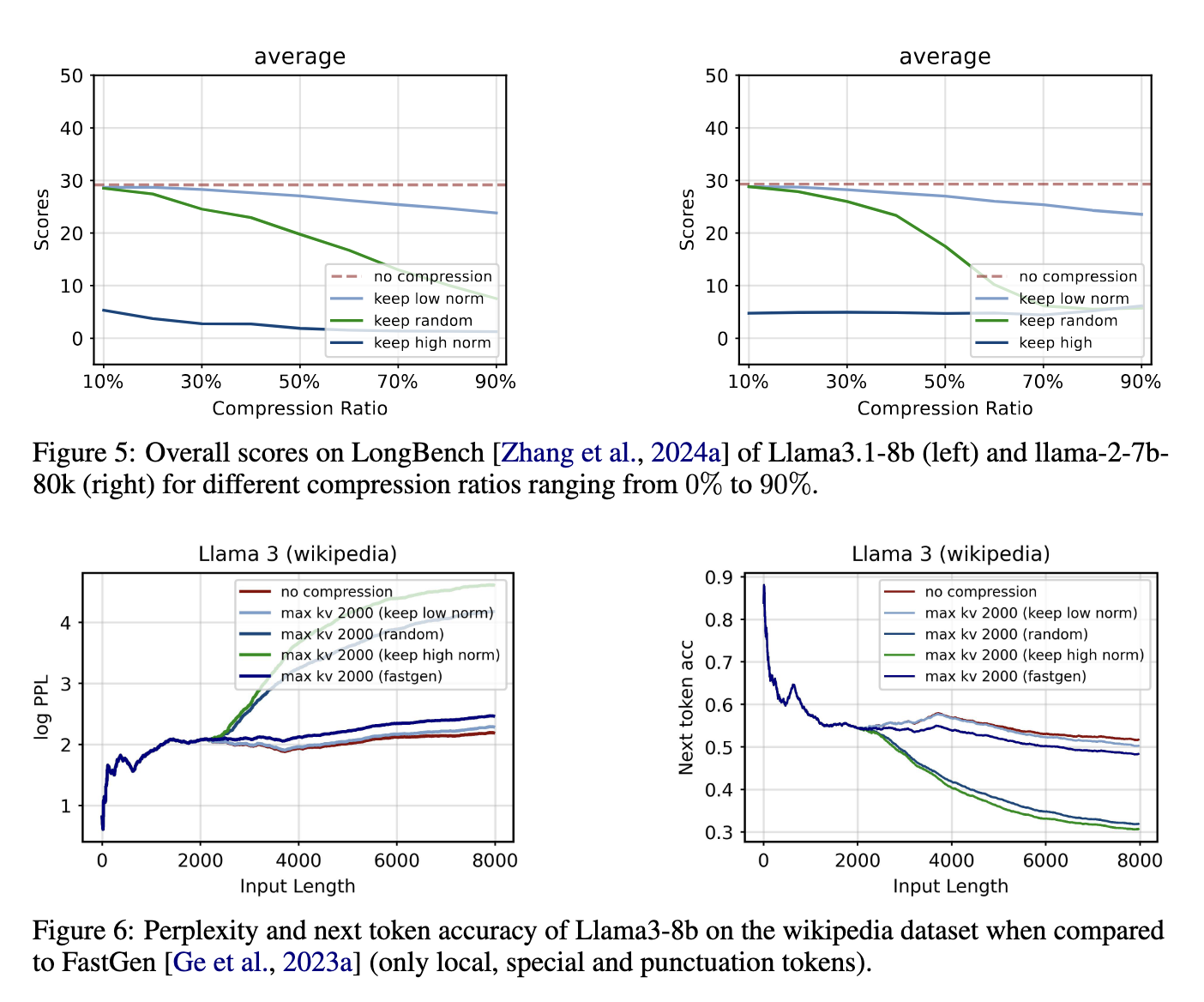
En cuanto al rendimiento, el método propuesto produce resultados notables en diversas tareas. Las evaluaciones experimentales mostraron que la compresión de la caché KV utilizando la estrategia de norma L2 redujo el uso de memoria hasta en un 50% en tareas generales de modelado de lenguaje, sin ningún impacto significativo en la perplejidad o precisión del modelo. Para las tareas que requieren recuperar información específica de contextos largos, como la tarea de recuperación de claves de acceso, el modelo logró una precisión del 100 % incluso al comprimir el 90 % de la caché KV. Estos resultados resaltan la efectividad de la estrategia de compresión para mantener el rendimiento del modelo y al mismo tiempo reducir sustancialmente los requisitos de memoria.
Además, el método demostró un rendimiento sólido en tareas desafiantes de contexto prolongado, como la prueba de la aguja en un pajar, donde el modelo necesita identificar y recuperar información crítica de un gran volumen de datos. En este escenario, el modelo mantuvo una precisión del 99 % al comprimir el 50 % de la caché KV, un testimonio de la confiabilidad de la estrategia de compresión. En comparación con los métodos existentes como FastGen, que se basan en puntuaciones de atención para la compresión, la estrategia basada en normas L2 proporciona una solución más simple y adaptable. Los resultados también indican que descartar pares KV con valores altos de norma L2 perjudica el rendimiento, ya que estos pares normalmente corresponden a incorporaciones menos informativas.
En conclusión, los investigadores de la Universidad de Edimburgo y la Universidad Sapienza de Roma han presentado una solución innovadora a un problema de larga data en la implementación de LLM. Su estrategia de compresión basada en normas L2 ofrece una forma práctica de gestionar el consumo de memoria de los LLM sin comprometer el rendimiento. Este enfoque es versátil, compatible con varias arquitecturas modelo y fácilmente implementable, lo que lo convierte en una valiosa contribución a los LLM. A medida que los LLM evolucionen y manejen tareas cada vez más complejas, estas estrategias de uso eficiente de la memoria permitirán una adopción más amplia en diferentes industrias y aplicaciones.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.