Ovis-1.6: una arquitectura de modelo de lenguaje grande multimodal (MLLM) de código abierto diseñada para alinear estructuralmente incrustaciones visuales y textuales

La inteligencia artificial (IA) se está transformando rápidamente, particularmente en el aprendizaje multimodal. Los modelos multimodales tienen como objetivo combinar información visual y textual para permitir que las máquinas comprendan y generen contenido que requiera entradas de ambas fuentes. Esta capacidad es vital para tareas como subtítulos de imágenes, respuesta visual a preguntas y creación de contenido, donde se requiere más de un único modo de datos. Si bien se han desarrollado muchos modelos para abordar estos desafíos, solo algunos han alineado de manera efectiva las representaciones dispares de datos visuales y textuales, lo que genera ineficiencias y un rendimiento subóptimo en aplicaciones del mundo real.
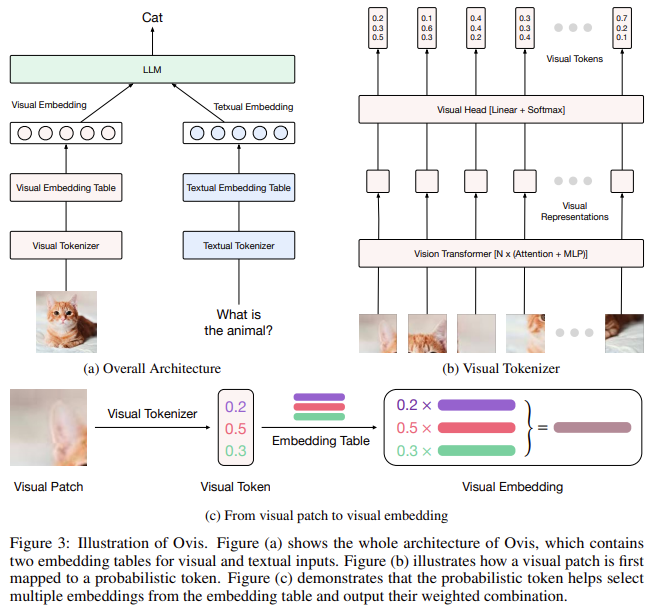
Un desafío importante en el aprendizaje multimodal surge de cómo se codifican y representan los datos de texto e imágenes. Los datos textuales normalmente se definen mediante incrustaciones derivadas de una tabla de búsqueda, lo que garantiza un formato estructurado y coherente. Por el contrario, los datos visuales se codifican mediante transformadores de visión, que producen incrustaciones continuas no estructuradas. Esta discrepancia en la representación facilita que los modelos multimodales existentes fusionen datos visuales y textuales a la perfección. Como resultado, los modelos tienen dificultades para interpretar relaciones visuales y textuales complejas, lo que limita sus capacidades en aplicaciones avanzadas de IA que requieren una comprensión coherente de múltiples modalidades de datos.
Tradicionalmente, los investigadores han intentado mitigar este problema mediante el uso de un conector, como un perceptrón multicapa (MLP), para proyectar incrustaciones visuales en un espacio que pueda alinearse con incrustaciones textuales. Si bien es eficaz en tareas multimodales estándar, esta arquitectura debe resolver la desalineación fundamental entre las incrustaciones visuales y textuales. Los modelos líderes como LLaVA y Mini-Gemini incorporan métodos avanzados como mecanismos de atención cruzada y codificadores de visión dual para mejorar el rendimiento. Sin embargo, todavía enfrentan limitaciones debido a las diferencias inherentes en las estrategias de tokenización e integración, lo que destaca la necesidad de un enfoque novedoso que aborde estos problemas a nivel estructural.
Presentado un equipo de investigación del Grupo Alibaba y la Universidad de Nanjing ovisun nuevo modelo multimodal de lenguaje grande (MLLM) que alinea estructuralmente incrustaciones visuales y textuales para abordar este desafío. Ovis emplea una tabla de búsqueda de incrustaciones visuales única, similar a la utilizada para incrustaciones textuales, para crear representaciones visuales estructuradas. Esta tabla permite que el codificador visual produzca incrustaciones compatibles con incrustaciones textuales, lo que resulta en una integración de información visual y textual más efectiva. El modelo también utiliza tokens probabilísticos para parches visuales mapeados en la tabla de incrustación visual varias veces. Este enfoque refleja la representación estructurada utilizada en los datos textuales, facilitando una combinación coherente de entradas visuales y textuales.
La principal innovación de Ovis radica en el uso de una tabla de incrustación visual que alinea los tokens visuales con sus contrapartes textuales. Un token probabilístico representa cada parche de imagen e indexa la tabla de incrustación visual varias veces para generar una incrustación visual final. Este proceso captura la rica semántica de cada parche visual y da como resultado incrustaciones estructuralmente similares a los tokens textuales. A diferencia de los métodos convencionales, que se basan en proyecciones lineales para mapear incrustaciones visuales en un espacio conjunto, Ovis adopta un enfoque probabilístico para generar incrustaciones visuales más significativas. Este método permite a Ovis superar las limitaciones de las arquitecturas basadas en conectores y lograr un mejor rendimiento en tareas multimodales.
Las evaluaciones empíricas de Ovis demuestran su superioridad sobre otros MLLM de código abierto de tamaños similares. Por ejemplo, en el benchmark MathVista-Mini, Ovis obtuvo una puntuación de 1808, significativamente más alta que la de sus competidores. De manera similar, en el punto de referencia RealWorldQA, Ovis superó a los modelos propietarios líderes como GPT4V y Qwen-VL-Plus, con una puntuación de 2230, en comparación con el 2038 de GPT4V. Estos resultados resaltan la fortaleza de Ovis en el manejo de tareas multimodales complejas, lo que lo convierte en un candidato prometedor para futuros avances en el campo. Los investigadores también evaluaron a Ovis en una serie de puntos de referencia multimodales generales, incluidos MMBench y MMStar, donde superó consistentemente a modelos como Mini-Gemini-HD y Qwen-VL-Chat por un margen del 7,8% al 14,1%, dependiendo del punto de referencia específico. .

Conclusiones clave de la investigación:
- Alineación estructural: Ovis presenta una novedosa tabla de incrustación visual que alinea estructuralmente las incrustaciones visuales y textuales, mejorando la capacidad del modelo para procesar datos multimodales.
- Rendimiento superior: Ovis supera a los modelos de código abierto de tamaños similares en varios puntos de referencia, logrando una mejora del 14,1% con respecto a las arquitecturas basadas en conectores.
- Capacidades de alta resolución: El modelo sobresale en tareas que requieren comprensión visual de imágenes de alta resolución, como el punto de referencia RealWorldQA, donde obtuvo una puntuación de 2230, superando a GPT4V por 192 puntos.
- Escalabilidad: Ovis demuestra un rendimiento consistente en diferentes niveles de parámetros (7B, 14B), lo que lo hace adaptable a varios tamaños de modelos y recursos computacionales.
- Aplicaciones prácticas: Con sus capacidades multimodales avanzadas, Ovis se puede aplicar a escenarios complejos y desafiantes del mundo real, incluida la respuesta visual a preguntas y los subtítulos de imágenes, donde los modelos existentes tienen dificultades.
En conclusión, los investigadores han abordado con éxito la antigua desalineación entre las incrustaciones visuales y textuales. Al introducir una estrategia de incrustación visual estructurada, Ovis permite una integración de datos multimodal más eficaz, mejorando el rendimiento en diversas tareas. La capacidad del modelo para superar a los modelos propietarios y de código abierto de escalas de parámetros similares, como Qwen-VL-Max, subraya su potencial como un nuevo estándar en el aprendizaje multimodal. El enfoque del equipo de investigación ofrece un importante paso adelante en el desarrollo de MLLM, proporcionando nuevas vías para futuras investigaciones y aplicaciones.
Mira el Papel, GitHuby Modelo HF. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.