AutoCE: un asesor de modelos inteligente que revoluciona la estimación de cardinalidad para bases de datos mediante técnicas avanzadas de aprendizaje métrico profundo y aprendizaje incremental

La estimación de cardinalidad (CE) es esencial para muchas tareas relacionadas con bases de datos, como la generación de consultas, la estimación de costos y la optimización de consultas. Es necesario un CE preciso para garantizar una planificación y ejecución óptimas de las consultas dentro de un sistema de base de datos. La adopción de técnicas de aprendizaje automático (ML) ha introducido nuevas posibilidades para la CE, lo que permite a los investigadores aprovechar las sólidas capacidades de aprendizaje y representación de los modelos ML. Al utilizar estos modelos, es factible lograr una mayor precisión de estimación y reducir la latencia de procesamiento, lo que convierte a los modelos CE basados en ML en un área de estudio prometedora para los sistemas modernos de gestión de bases de datos.
Uno de los principales desafíos que enfrenta la CE es la naturaleza diversa de los conjuntos de datos utilizados en aplicaciones del mundo real. Las variaciones en las características de los datos, como el número de tablas, las condiciones de unión, las correlaciones y la asimetría, pueden provocar fluctuaciones en el rendimiento de diferentes modelos de CE. Esta variabilidad dificulta la selección de un modelo único que ofrezca consistentemente un rendimiento óptimo en varios conjuntos de datos. Ya sea que se basen en consultas o en datos, los enfoques tradicionales de CE luchan por generalizar su desempeño, lo que a menudo resulta en una precisión y eficiencia inferiores en ciertos escenarios.
Dos categorías principales de métodos CE existentes son los modelos basados en consultas y los modelos basados en datos. Los modelos basados en consultas codifican la relación entre las consultas y sus cardinalidades aprovechando la información de la carga de trabajo, mientras que los modelos basados en datos se centran en capturar la distribución conjunta del propio conjunto de datos. Ejemplos notables incluyen DeepDB, NeuroCard y MSCN, cada uno de los cuales muestra distintas fortalezas y debilidades según la complejidad del conjunto de datos. Por ejemplo, mientras que MSCN supera a otros en un entorno de tablas múltiples como el conjunto de datos IMDB, NeuroCard es más adecuado para conjuntos de datos simples de una sola tabla. Estas limitaciones hacen que sea crucial desarrollar una estrategia de selección de modelos CE que se adapte dinámicamente a las características del conjunto de datos.
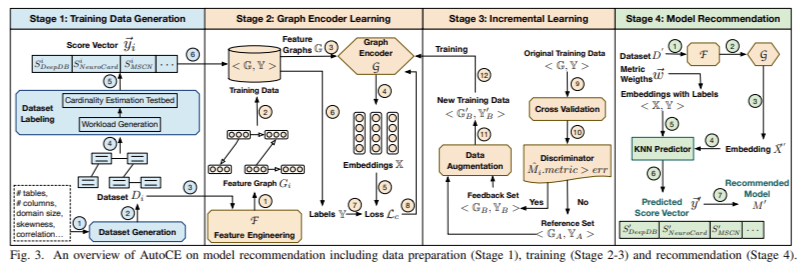
Se presentan investigadores de la Universidad de Tsinghua y del Instituto de Tecnología de Beijing AutoCEun asesor de modelos inteligente que selecciona automáticamente el mejor modelo CE para un conjunto de datos determinado. AutoCE utiliza un enfoque basado en el aprendizaje profundo para conocer la relación entre las características del conjunto de datos y el rendimiento de varios modelos CE. Integra un novedoso motor de recomendación basado en un aprendizaje métrico profundo, que permite al asesor identificar y recomendar rápidamente el modelo CE más adecuado sin una capacitación ni pruebas exhaustivas del modelo. AutoCE es particularmente eficaz en entornos donde los conjuntos de datos son dinámicos y cambian con frecuencia en estructura o tamaño.
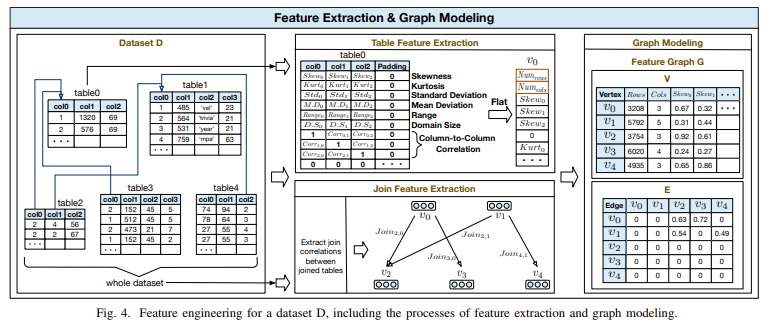
La tecnología central detrás de AutoCE implica extraer un conjunto completo de características de cada conjunto de datos, que luego se codifican como un gráfico de características. Este gráfico se utiliza para entrenar un codificador de gráficos basado en aprendizaje métrico profundo. Durante la fase de entrenamiento, el codificador de gráficos aprende a capturar las similitudes y diferencias entre conjuntos de datos con respecto a cómo afectan el rendimiento del modelo CE. Para refinar aún más sus predicciones, AutoCE emplea una estrategia de aprendizaje incremental. Esta estrategia implica identificar muestras mal predichas y generar nuevos datos de entrenamiento combinando muestras bien predichas, mejorando así la solidez del asesor con el tiempo.
La evaluación del desempeño de AutoCE frente a modelos CE establecidos demostró mejoras significativas. La herramienta logró un aumento del 27 % en el rendimiento general y sus métricas de precisión y eficiencia mejoraron 2,1 y 4,2 veces, respectivamente, en comparación con los métodos tradicionales. Por ejemplo, en el conjunto de datos de IMDB, el modelo MSCN tenía una métrica de error Q de 3, mientras que DeepDB y NeuroCard obtuvieron puntuaciones de 4 y 6, respectivamente. Sin embargo, en el conjunto de datos de Power, el modelo NeuroCard superó a los demás con un error Q de 2, mientras que MSCN obtuvo cuatro y DeepDB obtuvo 5. Esta variación indica la necesidad de un asesor de modelos como AutoCE, que pueda tomar decisiones informadas basadas en el conjunto de datos. -características específicas.
Las conclusiones clave de la investigación son:
- Eficiencia mejorada: AutoCE logró una mejora del 27 % en el rendimiento general en comparación con los modelos básicos.
- Precisión mejorada: AutoCE superó a los modelos existentes en precisión, aumentando 2,1 veces la precisión de la estimación.
- Reducción de Latencia: La herramienta redujo la latencia de un extremo a otro (E2E) en 4,2 veces, lo que mejoró significativamente los tiempos de respuesta a las consultas.
- Selección de modelo adaptativo: AutoCE puede adaptarse a diferentes características del conjunto de datos y elegir el modelo CE más adecuado sin necesidad de un reentrenamiento extenso.
- Capacidad de integración: AutoCE se integró con éxito en PostgreSQL v13.1, demostrando su utilidad práctica en sistemas de bases de datos del mundo real.

En conclusión, AutoCE presenta una solución convincente al problema de la selección del modelo CE aprovechando técnicas avanzadas de aprendizaje profundo. Su capacidad para aprender de diversos conjuntos de datos y mejorar gradualmente el rendimiento avanza significativamente en la optimización de las consultas de la base de datos. La investigación destaca el potencial de los asesores de modelos inteligentes para transformar los sistemas de gestión de bases de datos al proporcionar un método que optimiza la precisión y la eficiencia para diversas aplicaciones con uso intensivo de datos.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de 52k+ ML.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.