WaveletGPT: Aprovechamiento de la teoría Wavelet para una formación de LLM más rápida en todas las modalidades

Los grandes modelos de lenguaje (LLM) han revolucionado la inteligencia artificial y han impactado diversas disciplinas científicas y de ingeniería. La arquitectura Transformer, inicialmente diseñada para la traducción automática, se ha convertido en la base de los modelos GPT, lo que ha hecho avanzar significativamente este campo. Sin embargo, los LLM actuales enfrentan desafíos en su enfoque de capacitación, que se enfoca principalmente en predecir el próximo token en función del contexto anterior manteniendo la causalidad. Este método sencillo se ha aplicado en diversos dominios, incluida la robótica, las secuencias de proteínas, el procesamiento de audio y el análisis de vídeo. A medida que los LLM continúan creciendo en escala, alcanzando cientos de miles de millones e incluso billones de parámetros, surgen preocupaciones sobre la accesibilidad de la investigación en IA, y algunos temen que pueda quedar confinada a los investigadores de la industria. El problema central que están abordando los investigadores es cómo mejorar las capacidades del modelo para que coincidan con las de arquitecturas mucho más grandes o lograr un rendimiento comparable con menos pasos de capacitación, abordando en última instancia los desafíos de escala y eficiencia en el desarrollo de LLM.
Los investigadores han explorado varios enfoques para mejorar el rendimiento del LLM mediante la manipulación de incrustaciones intermedias. Un método implicó la aplicación de filtros ajustados a mano a la Transformada de Coseno Discreto del espacio latente para tareas como el reconocimiento de entidades con nombre y el modelado de temas en arquitecturas no causales como BERT. Sin embargo, este enfoque, que transforma toda la longitud del contexto, no es adecuado para tareas de modelado de lenguaje causal.
Dos técnicas notables, FNet y WavSPA, intentaron mejorar los bloques de atención en arquitecturas tipo BERT. FNet reemplazó el mecanismo de atención con un bloque FFT 2-D, pero esta operación no fue causal, considerando tokens futuros. WavSPA calculó la atención en el espacio wavelet, utilizando transformaciones de resolución múltiple para capturar dependencias a largo plazo. Sin embargo, también se basó en operaciones no causales, examinando toda la longitud de la secuencia.
Estos métodos existentes, si bien son innovadores, enfrentan limitaciones en su aplicabilidad a arquitecturas de solo decodificador causal como GPT. A menudo violan el supuesto de causalidad crucial para las tareas de predicción del siguiente token, lo que los hace inadecuados para la adaptación directa a modelos tipo GPT. El desafío sigue siendo desarrollar técnicas que puedan mejorar el rendimiento del modelo manteniendo la naturaleza causal de las arquitecturas de solo decodificador.
Investigadores de Stanford proponen la primera instancia de incorporación de wavelets en LLM, WaveletGPTpara mejorar los LLM mediante la incorporación de wavelets en su arquitectura. Esta técnica, que se cree que es la primera de su tipo, agrega filtros multiescala a las incrustaciones intermedias de las capas del decodificador Transformer utilizando ondas de Haar. La innovación permite que cada predicción del siguiente token acceda a representaciones de múltiples escalas en cada capa, en lugar de depender de representaciones de resolución fija.
Sorprendentemente, este método acelera el entrenamiento previo de los LLM basados en transformadores entre un 40% y un 60% sin agregar parámetros adicionales, un avance significativo dado el uso generalizado de arquitecturas basadas en Transformer Decoder en varias modalidades. El enfoque también demuestra mejoras sustanciales en el rendimiento con la misma cantidad de pasos de entrenamiento, comparables a agregar varias capas o parámetros.
La operación basada en wavelets muestra mejoras en el rendimiento en tres modalidades diferentes: lenguaje (texto-8), audio sin procesar (YoutubeMix) y música simbólica (MAESTRO), destacando su versatilidad para conjuntos de datos estructurados. Además, al hacer que los núcleos wavelet sean aprendibles, lo que agrega solo una pequeña fracción de parámetros, el modelo logra aumentos de rendimiento aún mayores, lo que le permite aprender filtros multiescala en incorporaciones intermedias desde cero.
El método propuesto incorpora wavelets en modelos de lenguaje grande basados en transformadores manteniendo al mismo tiempo el supuesto de causalidad. Este enfoque se puede aplicar a varias arquitecturas, incluidas las configuraciones sin transformador. La técnica se centra en manipular incrustaciones intermedias de cada capa de decodificador.
Para una señal dada xl(i), que representa la salida de la l-ésima capa de decodificador a lo largo de la i-ésima coordenada, el método aplica una transformada wavelet discreta. Con N+1 capas y una dimensión de incrustación E, este proceso genera N*E señales de longitud L (longitud de contexto) a partir de incrustaciones intermedias entre bloques decodificadores.
La transformada wavelet, específicamente utilizando wavelets de Haar, implica pasar la señal a través de filtros con diferentes resoluciones. Las wavelets de Haar son funciones de forma cuadrada derivadas de una wavelet madre mediante operaciones de escala y desplazamiento. Este proceso crea ondas secundarias que capturan información de señales en varias escalas de tiempo.
La transformada wavelet discreta se implementa pasando la señal a través de filtros de paso bajo y paso alto, seguido de una reducción de resolución. Para las wavelets de Haar, esto equivale a operaciones de promediación y diferenciación. El proceso genera coeficientes de aproximación (yapprox) y coeficientes de detalle (ydetail) mediante convolución y reducción de resolución. Esta operación se realiza de forma recursiva en los coeficientes de aproximación para obtener representaciones de múltiples escalas, lo que permite que cada predicción del siguiente token acceda a estas representaciones de múltiples resoluciones de incrustaciones intermedias.
Este método conecta wavelets e incrustaciones de LLM centrándose en coeficientes de aproximación, que capturan datos estructurados en varios niveles. Para el texto, esta estructura abarca desde letras hasta modelos temáticos, mientras que para la música simbólica abarca desde notas hasta piezas enteras. El enfoque utiliza wavelets de Haar, simplificando el proceso a una operación de media móvil. Para mantener la causalidad y la longitud de la secuencia original, el método calcula promedios móviles de muestras anteriores dentro de una longitud de núcleo específica para cada dimensión del token. Esto crea representaciones de múltiples escalas de la señal de entrada, lo que permite que el modelo capture información a diferentes resoluciones en las dimensiones de incrustación sin alterar la estructura de las incrustaciones intermedias de Transformer.

El método introduce un enfoque único para incorporar representaciones de múltiples escalas sin aumentar la complejidad arquitectónica. En lugar de calcular todos los niveles de señales aproximadas para cada dimensión de incrustación, parametrizó el nivel mediante el índice de la propia dimensión de incrustación. Este enfoque retiene la mitad de las señales de incrustación intermedias sin cambios, mientras procesa la otra mitad en función de su índice. Para la mitad procesada, una función de mapeo simple f determina el tamaño del núcleo para cada coordenada, desde aproximaciones de nivel I a IX. La señal modificada xnl(i) se calcula utilizando un filtro de media móvil causal con un tamaño de núcleo determinado por f(i). Esta operación mantiene el supuesto de causalidad crítico en los LLM y evita la fuga de información de tokens futuros. La técnica crea una estructura donde diferentes dimensiones de incrustación se mueven a diferentes velocidades, lo que permite que el modelo capture información a varias escalas. Esta estructura de múltiples velocidades permite que el mecanismo de atención utilice funciones de múltiples escalas en cada capa y token, lo que potencialmente mejora la capacidad del modelo para capturar patrones complejos en los datos.
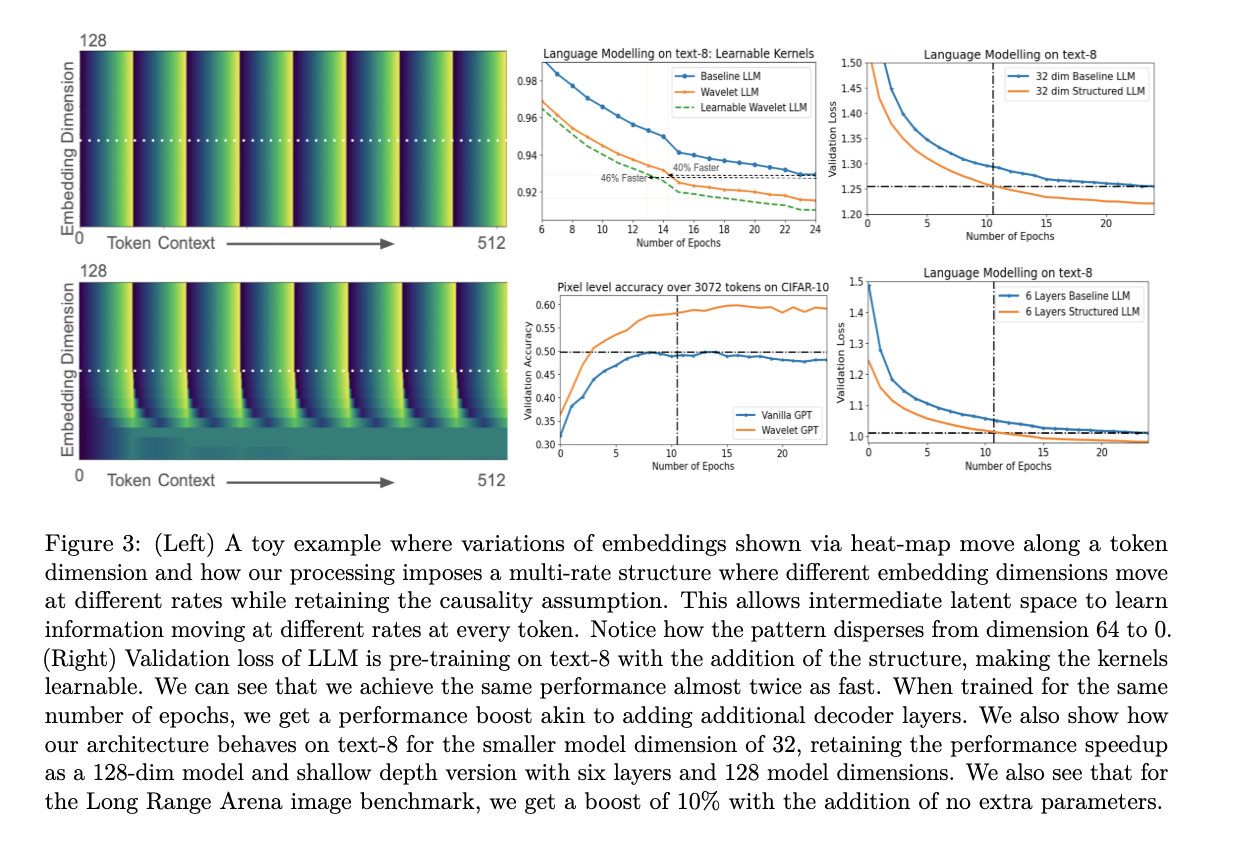
Los resultados en tres modalidades (texto, música simbólica y formas de onda de audio) demuestran mejoras sustanciales en el rendimiento con la operación intermedia basada en wavelets. Para el lenguaje natural, la disminución en la pérdida de validación equivale a expandirse de un modelo de 16 capas a uno de 64 capas en el conjunto de datos de texto 8. La arquitectura modificada logra la misma pérdida casi dos veces más rápido que la original en términos de pasos de entrenamiento. Esta aceleración es aún más pronunciada para el audio sin procesar, posiblemente debido a la naturaleza casi estacionaria de las señales de audio en escalas de tiempo cortas. La convergencia de las configuraciones LLM de forma de onda sin procesar ocurre casi dos veces más rápido en comparación con el texto-8 y la música simbólica.
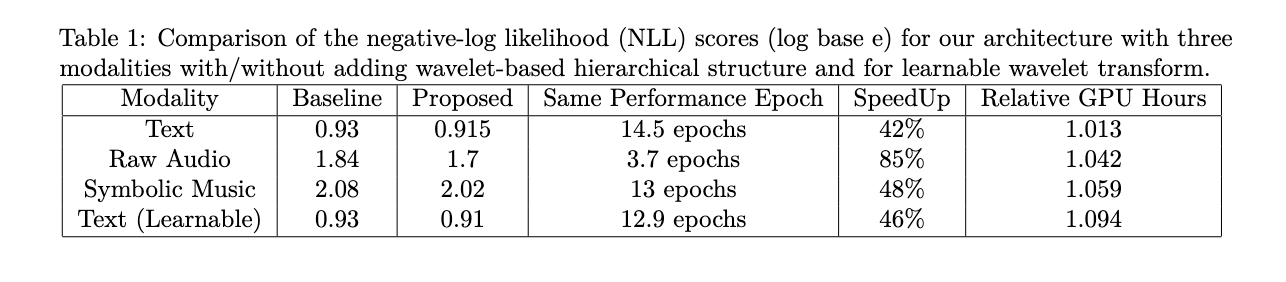
Al comparar los tiempos de ejecución absolutos del reloj, la arquitectura modificada muestra eficiencia computacional tanto en configuraciones que se pueden aprender como en las que no se pueden aprender. Se informa el tiempo necesario para completar una época en relación con la arquitectura de referencia. El método demuestra ser económico desde el punto de vista computacional, ya que la operación principal implica un promedio simple para las wavelets de Haar o el aprendizaje de un núcleo convolucional de filtro único con longitudes de contexto variables en las dimensiones de incrustación. Esta eficiencia, combinada con las mejoras de rendimiento, subraya la eficacia del enfoque basado en wavelets para mejorar la formación LLM en diversas modalidades sin una sobrecarga computacional significativa.
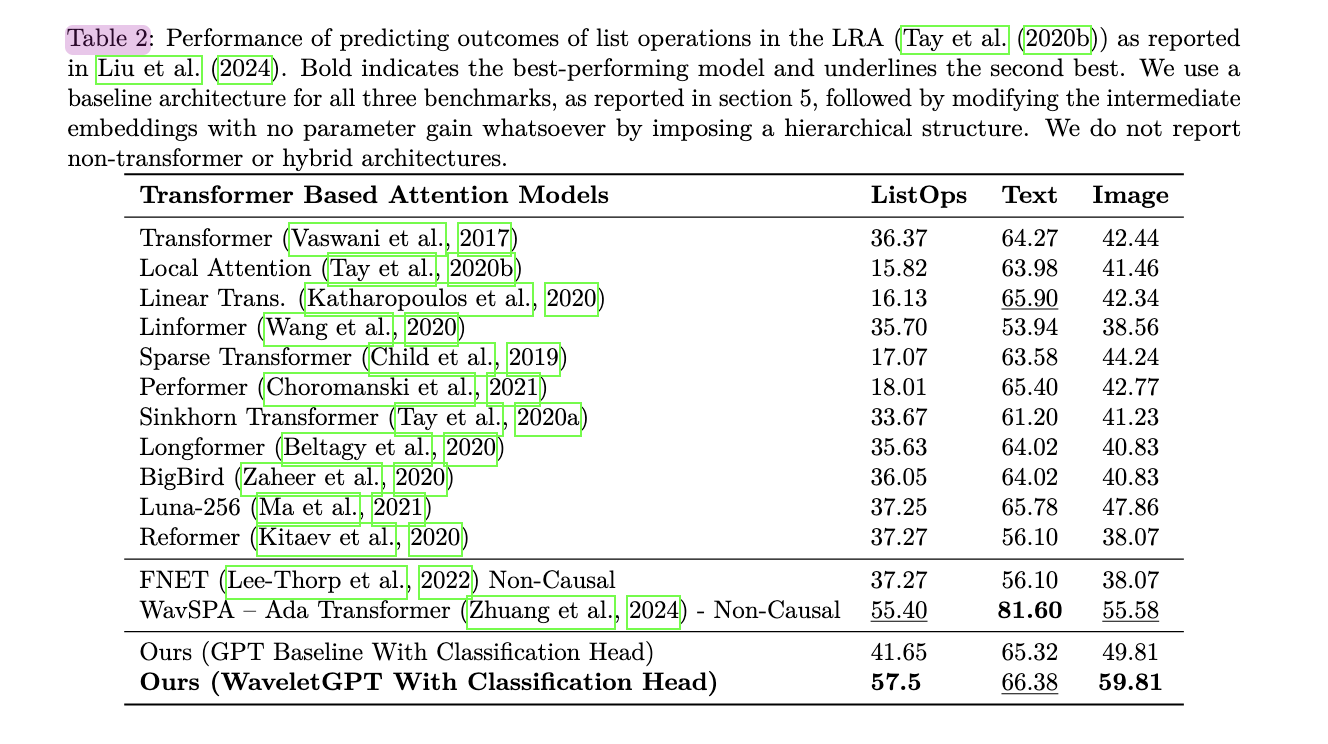
Este estudio presenta WaveletGPT, que presenta la integración de wavelets, una técnica central de procesamiento de señales, en el preentrenamiento de modelos de lenguaje grandes. Al introducir una estructura de múltiples escalas en las incrustaciones intermedias, la velocidad de rendimiento mejora entre un 40 y un 60 % sin agregar ningún parámetro adicional. Esta técnica resulta eficaz en tres modalidades diferentes: texto sin formato, música simbólica y audio sin formato. Cuando se entrena durante la misma duración, demuestra mejoras sustanciales en el rendimiento. Las posibles direcciones futuras incluyen la incorporación de conceptos avanzados de wavelets y procesamiento de señales de resolución múltiple para optimizar aún más los modelos de lenguaje grandes.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología, Kharagpur. Asjad es un entusiasta del aprendizaje automático y el aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención médica.