Investigadores del MIT y la Universidad de Pekín presentan un mecanismo de autocorrección para mejorar la seguridad y confiabilidad de modelos de lenguaje grandes

Los mecanismos de autocorrección han sido un importante tema de interés dentro de la inteligencia artificial, particularmente en los modelos de lenguaje grande (LLM). La autocorrección se considera tradicionalmente un rasgo humano distintivo. Aún así, los investigadores han comenzado a investigar cómo se puede aplicar a los LLM para mejorar sus capacidades sin requerir aportes externos. Esta área emergente explora formas de permitir que los LLM evalúen y refinen sus respuestas, haciéndolos más autónomos y efectivos para comprender tareas complejas y generar respuestas contextualmente apropiadas.
Los investigadores pretenden abordar un problema crítico: la dependencia de los LLM de críticos externos y supervisión predefinida para mejorar la calidad de la respuesta. Los modelos convencionales, aunque potentes, a menudo dependen de la retroalimentación humana o de evaluadores externos para corregir errores en el contenido generado. Esta dependencia limita su capacidad para mejorar y funcionar de forma independiente. Una comprensión integral de cómo los LLM pueden corregir sus errores de forma autónoma es esencial para construir sistemas más avanzados que puedan funcionar sin una validación externa constante. Lograr esta comprensión puede revolucionar la forma en que los modelos de IA aprenden y evolucionan.
La mayoría de los métodos existentes en este campo incluyen el aprendizaje reforzado a partir de la retroalimentación humana (RLHF) o la optimización directa de preferencias (DPO). Estos métodos suelen incorporar críticos externos o datos de preferencias humanas para guiar a los LLM a refinar sus respuestas. Por ejemplo, en RLHF, un modelo recibe retroalimentación de los humanos sobre sus respuestas generadas y utiliza esa retroalimentación para ajustar sus resultados posteriores. Aunque estos métodos han tenido éxito, no permiten que los modelos mejoren sus comportamientos de forma autónoma. Esta limitación presenta un desafío en el desarrollo de LLM que puedan identificar y corregir sus errores de forma independiente, lo que requiere enfoques novedosos para mejorar las habilidades de autocorrección.
Investigadores del MIT CSAIL, la Universidad de Pekín y la TU Munich han introducido un marco teórico innovador basado en la alineación en contexto (ICA). La investigación propone un proceso estructurado donde los LLM utilizan mecanismos internos para autocrítica y refinar las respuestas. Al adoptar una metodología de generación-crítica-regeneración, el modelo comienza con una respuesta inicial, critica su desempeño internamente utilizando una métrica de recompensa y luego genera una respuesta mejorada. El proceso se repite hasta que el resultado cumpla con un estándar de alineación más alto. Este método transforma el contexto tradicional (consulta, respuesta) en un formato triplete más complejo (consulta, respuesta, recompensa). El estudio sostiene que dicha formulación ayuda a los modelos a evaluarse y alinearse de manera más efectiva sin requerir objetivos predefinidos guiados por humanos.
Los investigadores utilizaron una arquitectura de transformador multicapa para implementar el mecanismo de autocorrección propuesto. Cada capa consta de módulos de red de retroalimentación y autoatención de múltiples cabezales que permiten al modelo discernir entre respuestas buenas y malas. Específicamente, la arquitectura fue diseñada para permitir a los LLM realizar un descenso de gradiente a través del aprendizaje en contexto, lo que permite una comprensión más dinámica y matizada de las tareas de alineación. A través de experimentos con datos sintéticos, los investigadores validaron que los transformadores realmente podían aprender de las salidas ruidosas cuando eran guiados por críticos precisos. Las contribuciones teóricas del estudio también arrojan luz sobre cómo componentes arquitectónicos específicos como la atención softmax y las redes de retroalimentación son cruciales para permitir una alineación efectiva en contexto, estableciendo un nuevo estándar para las arquitecturas basadas en transformadores.
La evaluación del desempeño reveló mejoras sustanciales en múltiples escenarios de prueba. El mecanismo de autocorrección redujo significativamente las tasas de error y mejoró la alineación en los LLM, incluso en situaciones que involucran retroalimentación ruidosa. Por ejemplo, el método propuesto mostró una reducción drástica en las tasas de éxito de los ataques durante las pruebas de jailbreak, con una tasa de éxito que cayó del 95% a tan solo el 1% en ciertos escenarios que utilizan LLM como Vicuña-7b y Llama2-7b-chat. Los resultados indicaron que los mecanismos de autocorrección podrían defenderse contra ataques sofisticados de jailbreak como GCG-individual, GCG-transfer y AutoDAN. Este sólido desempeño sugiere que los LLM autocorregibles tienen el potencial de ofrecer mayor seguridad y solidez en aplicaciones del mundo real.
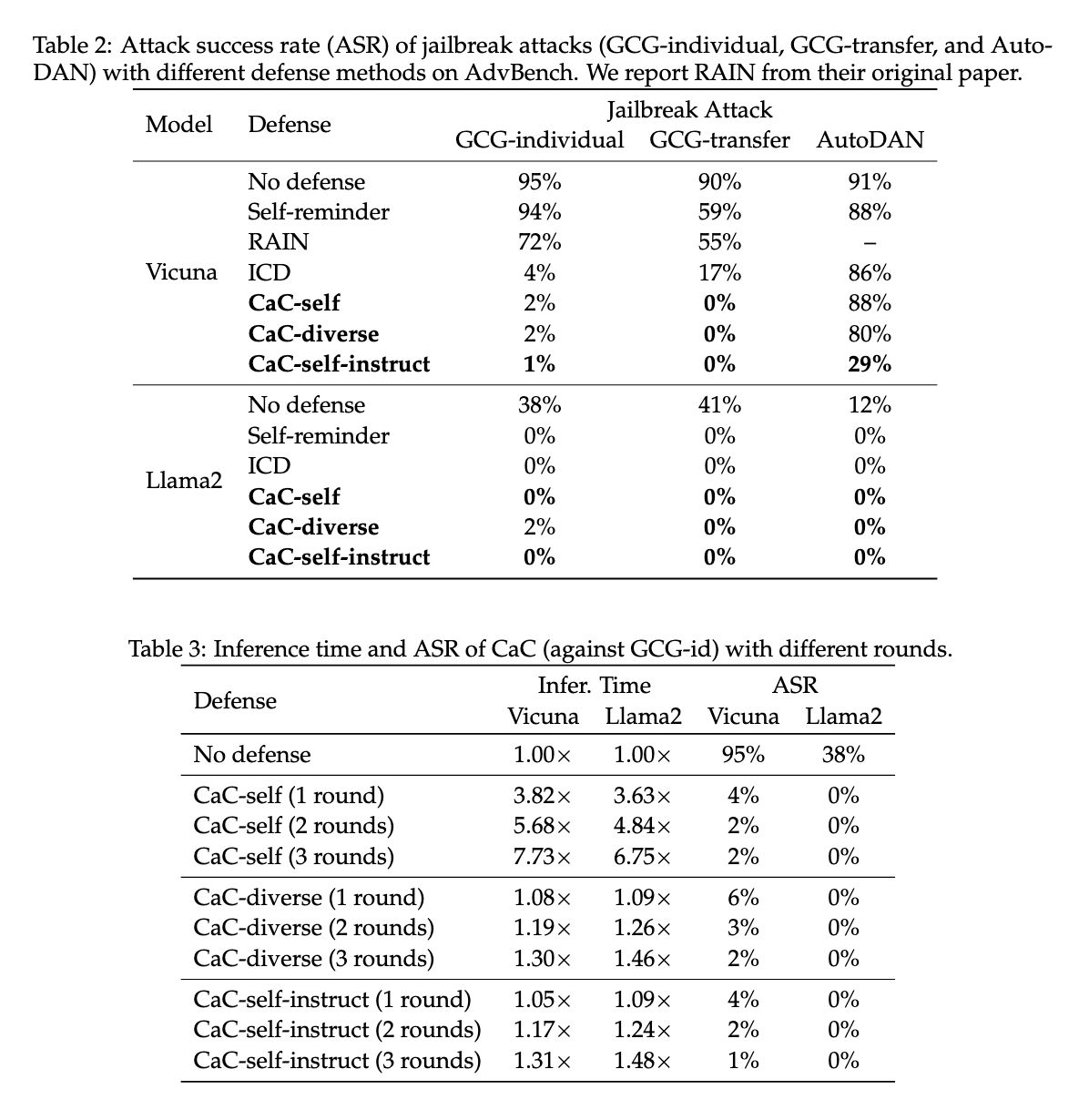
El método de autocorrección propuesto también mejoró significativamente en experimentos que abordaban prejuicios sociales. Cuando se aplicó al conjunto de datos Bias Benchmark for QA (BBQ), que evalúa los sesgos en nueve dimensiones sociales, el método logró mejoras de desempeño en categorías como género, raza y estatus socioeconómico. El estudio demostró una tasa de éxito de ataque del 0 % en varias dimensiones de sesgo utilizando Llama2-7b-chat, lo que demuestra la eficacia del modelo para mantener la alineación incluso en contextos sociales complejos.
En conclusión, esta investigación ofrece un enfoque innovador para la autocorrección en los LLM, enfatizando el potencial de los modelos para refinar de forma autónoma sus resultados sin depender de retroalimentación externa. El uso innovador de arquitecturas transformadoras multicapa y alineación en contexto demuestra un camino claro a seguir para desarrollar modelos de lenguaje más autónomos e inteligentes. Al permitir que los LLM se autoevalúen y mejoren, el estudio allana el camino para la creación de sistemas de inteligencia artificial más sólidos, seguros y conscientes del contexto, capaces de abordar tareas complejas con una mínima intervención humana. Este avance podría mejorar significativamente el diseño y la aplicación futuros de los LLM en varios dominios, sentando las bases para modelos que no solo aprenden sino que también evolucionan de forma independiente.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml.
Estamos invitando a startups, empresas e instituciones de investigación que estén trabajando en modelos de lenguajes pequeños a participar en este próximo Revista/Informe ‘Small Language Models’ de Marketchpost.com. Esta revista/informe se publicará a finales de octubre o principios de noviembre de 2024. ¡Haga clic aquí para programar una llamada!
Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.